三剑客之awk 自动化运维监控脚本

三剑客之sed命令
一 awk简介
awk命名源自于它的三大作者名字的首字母,分别是Alfred Aho、Brian Kernighan、Peter
Weinberger。(gawk是awk的GNU版本,它提供了Bell实验室和GNU的一些扩展)。
awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入、一个
或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix
下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。
awk的处理文本和数据的方式是这样的,它逐行扫描文件,从第一行到最后一行,寻找匹配的特定
模式的行,并在这些行上进行你想要的操作。如果没有指定处理动作,则把匹配的行显示到标准输出(
屏幕),如果没有指定模式,则所有被操作所指定的行都被处理
awk的两种语法格式
awk [options] 'commands' filename
awk [options] -f awk-script-file filename
awk选项options
-F 定义字段分隔符,默认的分隔符是空格或制表符(tab)
awk的命令commands总共由三部分组成
BEGIN{} 读所有行之前做的事情
{} 读一行处理一行
END{} 所有读完之后要做的事情
可以省略BEGIN{} 和END{},只进行{}行处理,并且{}行处理前可以加匹配,匹配成功后再处理
例如
awk 'pattern' filename
示例:awk -F: '/root/' /etc/passwd
awk '{action}' filename
示例:awk -F: '{print 1}' /etc/passwd
awk 'pattern{action}' filename
示例:awk -F: '/root/{print1,3}' /etc/passwd
示例:awk 'BEGIN{FS=":"} /root/{print1,3}' /etc/passwd
其他命令 |awk 'pattern'
其他命令 |awk '{action}'
其他命令 |awk 'pattern{action}'
# 匹配pattern可以是:/正则表达式/也可以是条件,如下
示例:df -P |awk '4 > 999999{print 0}'
# 也可以省略{print0}
模式pattern还可以是其他,详解第五章节
二 awk工作原理
awk -F: '{print 1,3}' /etc/passwd
(1)awk会接收一行作为输入,并将这一行赋给awk的内部变量0,每一行也可称为一个记录,行的边界是以换行符作为结束.
(2)然后,刚刚读入的行被以:为分隔符分解成若干字段(或域),每个字段存储在已编号的变量中,编号从1开始,最多达100个字段.
注意:如果未指定行分隔符,awk将使用内置变量FS的值作为默认的行分隔符,FS默认值为空格.
(3)使用print函数打印,如果13之间没有逗号,它俩在输出时将贴在一起,应该在1,3之间加逗号,该逗号与awk的内置变量OFS保持一致,OFS默认为空格,于是以空格为分隔符输出1和3.
我们可以指定:awk -F: 'BEGIN{OFS="-"}{print 1,3}' /etc/passwd
(4)输出之后,将从文件中获取另一行,然后覆盖给$0,继续(2)的步骤将该行内容分隔成字段。。。继续(3)的步骤,该过程一直持续到所有行处理完毕
三 记录与字段相关内部变量
$0: 保存当前行的内容 # awk -F: '{print $0}' /etc/passwd
NR: 记录号,每处理完一条记录,NR值加1 # awk -F: '{print NR, $0}' /etc/passwd
NF: 保存记录的字段数,$1,$2...$100 # awk -F: '{print $0,NF}' /etc/passwd
FS: 输入字段分隔符,默认空格
# awk -F: '/alice/{print $1, $3}' /etc/passwd
# awk -F'[ :\t]' '{print $1,$2,$3}' /etc/passwd
# awk 'BEGIN{FS=":"} {print $1,$3}' /etc/passwd
OFS:输出字段分隔符
# awk -F: '/root/{print $1,$2,$3,$4}' /etc/passwd
# awk -F: 'BEGIN{OFS="+++"} /^root/{print $1,$2,$3,$4}' /etc/passwd
四 格式化输出
================print函数===================
[root@egon ~]# date | awk '{print "月:",2,"\n年:",1}'
月: 09月
年: 2020年
[root@egon ~]# awk -F: '{print "用户名:",1,"用户id:",3}' /etc/passwd
================printf函数===================
[root@egon ~]# awk -F: '{printf "用户名:%s 用户id:%s\n",1,3}' /etc/passwd
用户名:root 用户id:0
用户名:bin 用户id:1
用户名:daemon 用户id:2
用户名:adm 用户id:3
...
[root@egon ~]# awk -F: '{printf "|%-15s| %-5s| %-4s|\n", 1,2,$3}' /etc/passwd
|root | x | 0 |
|bin | x | 1 |
|daemon | x | 2 |
...
%s 字符类型
%d 数值类型
%-15s 整个占15格的字符串(左对齐)
%3s 整个占3格的字符串(右对齐)
- 表示左对齐,默认是右对齐
print与printf默认不会在行尾自动换行,要加\n
五 模式pattern与动作action
awk 'pattern{action}' filename
模式pattern可以是:
- 正则表达式
# 匹配整行
awk -F: '/egon/{print 1,3}' /etc/passwd
awk '/^root/' /etc/passwd
# 匹配一行的某个字段
awk '0 ~ /^root/' /etc/passwd
awk '1 ~ /^root/' /etc/passwd
awk '7 !~ /bash/' /etc/passwd
- 比较表达式
比较表达式指的是使用关系运算符来比较数字以及字符串,只有当条件为真,才执行指定的动作,默认输出该行.
关系运算符:
运算符 含义 示例
< 小于 x<y
<= 小于或等于 x<=y
== 等于 x==y
!= 不等于 x!=y
>= 大于等于 x>=y
> 大于 x>y
~ 正则表达式匹配 x~/y/
!~ 正则表达式不匹配 x!~/y/
# 示例:
[root@web ~]# awk -F: '3 == 0' /etc/passwd
root:x:0:0:root:/root:/bin/bash
awk -F: '3 < 10' /etc/passwd
awk -F: '7 == "/bin/bash"' /etc/passwd
awk -F: '1 == "root" ' /etc/passwd
- 条件表达式
[root@web ~]# awk -F: '{if(3>300) {print0}}' /etc/passwd
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
nginx:x:998:996:Nginx web server:/var/lib/nginx:/sbin/nologin
vvv:x:1000:1000::/home/vvv:/bin/bash
awk -F: '{if(3>300) {print3} else{print 1}}' /etc/passwd
awk -F: '{if(3>300) {max=3;print max} else{max=1;print max}}'
/etc/passwd
awk -F: '{max=(3>300) ?3 : 1; print max}' /etc/passwd
awk -F: '{if(3>4) {max=3;print max} else{max=4; print max}}'
/etc/passwd
awk -F: '{max=(3 > 4) ?3: 4; print max}' /etc/passwd
相当于:
if (3 > 4)
max=3
else
max=$4
- 算数运算
+ - * / %(模) ^(幂2^3)
可以在模式中执行计算,awk都将按浮点数方式执行算术运算
[root@zabbix ~]# awk -F: '3 * 10>500 {print1,$3}' /etc/passwd
nobody 99
systemd-network 192
dbus 81
polkitd 999
...
- 逻辑运算和复合模式
&& 逻辑与 a&&b
|| 逻辑或 a||b
! 逻辑非 !a
示例:
awk '2>5 &&2 <= 15' filename
awk '3 == 100 ||4 > 50' filename
awk '!(2<100 &&3 < 20)' filename
- 范围模式
awk '/root/,/egon/' filename
# 说明:
awk将显示从root首次出现的行到egon首次出现的行这个范围内的所有行,包括两个边界在内。如果没
有找到egon,awk将继续打印各行直至文件末尾。
如果打印完root到egon的内容之后,又出现了root, awk就又一次开始显示行,直至找到下一个
egon或文件末尾。
awk -F: 'NR>=1 && NR <=3 {print $1}' test.txt
六 awk示例
# awk '/west/' datafile
# awk '/^north/' datafile
# awk '/^(no|so)/' datafile
# awk '{print 3,2}' datafile
# awk '{print 32}' datafile
# awk '{print 0}' datafile
# awk '{print "Number of fields: "NF}' datafile
# awk '/northeast/{print3,2}' datafile
# awk '/E/' datafile
# awk '/^[ns]/{print1}' datafile
# awk '5 ~ /\.[7-9]+/' datafile
# awk '2 !~ /E/{print 1,2}' datafile
# awk '3 ~ /^Joel/{print3 " is a nice guy."}' datafile
# awk '8 ~ /[0-9][0-9]/{print 8}' datafile
# awk '4 ~ /Chin/{print "The price is" 8 "."}' datafile
# awk '/Tj/{print0}' datafile
# awk '{print 1}' datafile2
# awk -F: '{print1}' datafile2
# awk '{print "Number of fields: "NF}' datafile2
# awk -F: '{print "Number of fields: "NF}' datafile2
# awk -F"[ :]" '{print 1,2}' datafile2
# awk '7 == 5' datafile
# awk '2 == "CT" {print 1,2}' datafile
# awk '7 != 5' datafile
# awk '7 < 5 {print 4,7}' datafile
# awk '6>.9 {print1,6}' datafile
# awk '8 <= 17 {print 8}' datafile
# awk '8 >= 17 {print 8}' datafile
# awk '8 > 10 && 8<17' datafile
# awk '2 == "NW" || 1 ~ /south/ {print1, 2}' datafile
# awk '!(8 == 13){print 8}' datafile
# awk '/southem/{print5 + 10}' datafile
# awk '/southem/{print 8 + 10}' datafile
# awk '/southem/{print5 + 10.56}' datafile
# awk '/southem/{print 8 - 10}' datafile
# awk '/southem/{print8 / 2 }' datafile
# awk '/southem/{print 8 / 3 }' datafile
# awk '/southem/{print8 * 2 }' datafile
# awk '/southem/{print 8 % 2 }' datafile
# awk '3 ~ /^Suan/ {print "Percentage: "6 + .2" Volume: "8}' datafile
# awk '/^western/,/^eastern/' datafile
# awk '{print (7>4 ? "high "7 : "low "7)}' datafile //条件运算符
# awk '3 == "Chris" {3 = "Christian"; print}' datafile //赋值运算符
# awk '/Derek/ {8 += 12; print 8}' datafile //8 += 12等价于8 =8 + 12
# awk '{7 %= 3; print7}' datafile //7 %= 3等价于7 = $7 % 3
七 awk流程控制
==条件判断
if语句:
格式
{if(表达式){语句;语句;...}}
awk -F: '{if(3==0) print1 " is administrator."}' /etc/passwd
awk -F: '{if(3>0 &&3<500){count++; print 1}} END{print count}' /etc/passwd
//统计系统用户数
if...else语句:
格式
{if(表达式){语句;语句;...}else{语句;语句;...}}
awk -F: '{if(3==0){print 1} else {print7}}' /etc/passwd
awk -F: '{if(3>0) {count++} else{i++}' /etc/passwd
awk -F: '{if(3>0){count++} else{i++}} END{print "管理员个数: "i "\n系统用户数: "count}' /etc/passwd
if...else if...else语句:
格式
{if(表达式){语句;语句;...}else if(表达式){语句;语句;...}else if(表达式){语句;语
句;...}else{语句;语句;...}}
awk -F: '{if(3==0){i++} else if(3>499){k++} else{j++}} END{print i; print k;
print j}' /etc/passwd
awk -F: '{if(3==0){i++} else if(3>499){k++} else{j++}} END{print "管理员个数:
"i; print "普通用个数: "k; print "系统用户: "j}' /etc/passwd
==循环
while:
awk -F: '{i=1; while(i<=10) {print 0; i++}}' /etc/passwd //将每行打印10次
for:
awk -F: '{for(i=1;i<=10;i++) print0}' /etc/passwd //将每行打印10次
==数组
# awk -F: '{username[++i]=1} END{print username[1]}' /etc/passwd
root
# awk -F: '{username[i++]=1} END{print username[1]}' /etc/passwd
bin
# awk -F: '{username[i++]=1} END{print username[0]}' /etc/passwd
root
# awk -F: '{username[x++]=1} END{for(i=0;i<NR;i++) print i,username[i]}'
/etc/passwd
0 root
1 bin
2 daemon
3 adm
4 lp
5 sync
6 shutdown
7 halt
...
# awk -F: 'BEGIN{x=1} {user[x++]=1} END{for(i=1;i<=NR;i++) {print i,user[i]} }'
/etc/passwd
# awk -F: 'BEGIN{j=1} {if(3<5){user[j++]=1}} END{for(i=1;i<j;i++) {print
i,user[i]} }' /etc/passwd
# awk -F: 'BEGIN{i=1} {username[i]=1;i++}'
# awk -F: 'BEGIN{i=1} 3<10{username[i]=1;++i} END{for(j=1;j<i;j++){print
j,username[j]}}' /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
8 halt
9 mail
10 admin
========================================================
# awk -F: '{username[++x]=1} END{for(i=1;i<=NR;i++) {print i,username[i]}}'
passwd1
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
8 halt
9 mail
10 uucp
# awk -F: '{username[++x]=1} END{for(i in username) {print username[i]} }'
passwd1
adm
lp
sync
shutdown
halt
mail
uucp
root
bin
daemon
# awk -F: '{user_id[1]=3} END{for(i in user_id) {print i,user_id[i]}}' passwd1
bin 1
uucp 10
mail 8
sync 5
shutdown 6
adm 3
daemon 2
halt 7
root 0
lp 4
========================================================
统计用户名为4个字符的用户:
[root@aliyun ~]# awk -F: '1~/^..../{count++; print 1} END{print "count is: "
count}' /etc/passwd
root
sync
halt
mail
news
uucp
nscd
vcsa
pcap
sshd
dbus
jack
count is: 12
[root@aliyun ~]# awk -F: 'length(1)==4{count++; print $1} END{print "count is:
"count}' /etc/passwd
root
sync
halt
mail
news
uucp
nscd
vcsa
pcap
sshd
dbus
jack
count is: 12
例子:
1. 取得网卡IP(除ipv6以外的所有IP)
2. 获得内存使用情况
3. 获得磁盘使用情况
4. 清空本机的ARP缓存
5. 打印出/etc/hosts文件的最后一个字段(按空格分隔)
6. 打印指定目录下的目录名
[root@aliyun dir1]# arp -a |awk -F"[()]" '{print "arp -d", 2}'
arp -d 192.168.2.26
arp -d 192.168.2.44
arp -d 192.168.2.28
arp -d 192.168.2.130
arp -d 192.168.2.90
arp -d 192.168.2.18
arp -d 192.168.2.129
[root@aliyun dir1]# arp -a |awk -F"[()]" '{print "arp -d "2}' |sh
[root@aliyun ~]# awk -F: '{print 7}' /etc/passwd
[root@aliyun ~]# awk -F: '{printNF}' /etc/passwd
[root@aliyun ~]# awk -F: '{print (NF-1)}' /etc/passwd
[root@aliyun ~]# ll |grep '^d'
drwxr-xr-x 104 root root 12288 09-22 05:37 192.168.0.48
drwxr-xr-x 2 root root 4096 10-30 15:47 apache_log
drwxr-xr-x 2 root root 4096 10-30 15:23 awk
drwxr-xr-x 2 root root 4096 10-24 09:09 Desktop
drwxr-xr-x 12 root root 4096 10-08 06:12 LEMP_Soft
drwxr-xr-x 2 root root 4096 10-24 07:38 scripts
drwxr-xr-x 6 root root 4096 2012-03-29 uplayer
八 练习题
drwxr-xr-x 7 root root 4096 10-23 04:53 vmware
[root@aliyun ~]#
[root@aliyun ~]# ll |grep '^d' |awk '{printNF}'
192.168.0.48
apache_log
awk
Desktop
LEMP_Soft
scripts
uplayer
vmware
awk脚本:
user1.awk
BEGIN {
FS=":"
}
{
if(3==0){
print1
}
else{
print 7
}
}
user2.awk
BEGIN{
FS=":"
OFS="\t\t"
print "username\tuid"
print "-------------------"
}
{if(3==0){
print 1,3;i++
}
}
END{
print "-------------------"
print "total users is: "i
}
练习
已知一个变量 msg="I am a teacher, my name is egon",打印字符长度小于3的单词
# 方式一:
[root@egon /]# for i in msg;do [{#i} -lt 3 ] && echo i;done
I
am
a
my
is
# 方式二:
[root@egon /]# echomsg |xargs -n1 |awk '{if(length<3) print}'
I
am
a
my
is
# 方式三:
[root@egon /]# echo msg |awk '{for(i=1;i<=NF;i++) if(length(i)<3) print i}'
I
am
a
my
is
# 方式四:
[root@egon /]# echomsg |egrep -wo '[a-z]{1,3}'
am
a
my
is
shell队列实现线程并发控制
需求:并发检测1000台web服务器状态(或者并发为1000台web服务器分发文件等)如何用shell实现?
- 方案一:(这应该是大多数人都第一时间想到的方法吧)
思路:一个for循环1000次,顺序执行1000次任务。
实现:
#!/bin/bash
start_time=`date +%s` #定义脚本运行的开始时间
for ((i=1;i<=1000;i++))
do
sleep 1 #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'i;
done
stop_time=`date +%s` #定义脚本运行的结束时间
echo "TIME:`exprstop_time - $start_time`"
运行结果:
[root@iZ94yyzmpgvZ ~]# . test.sh
success1
success2
success3
success4
success5
success6
success7
........此处省略
success999
success1000
TIME:1000
代码解析以及问题:
一个for循环1000次相当于需要处理1000个任务,循环体用sleep 1代表运行一条命令需要的时间,用success$i来标示每条任务.
这样写的问题是,1000条命令都是顺序执行的,完全是阻塞时的运行,假如每条命令的运行时间是1秒的话,那么1000条命令的运行时间是1000秒,效率相当低,而我的要求是并发检测1000台web的存活,如果采用这种顺序的方式,那么假如我有1000台web,这时候第900台机器挂掉了,检测到这台机器状态所需要的时间就是900s,吃屎都吃不上热乎的。
所以,问题的关键集中在一点:如何并发
- 方案二:
思路:一个for循环1000次,循环体里面的每个任务都放入后台运行(在命令后面加&符号代表后台运行)。
实现:
#!/bin/bash
start=`date +%s` #定义脚本运行的开始时间
for ((i=1;i<=1000;i++))
do
{
sleep 1 #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'i; }& #用{}把循环体括起来,后加一个&符号,代表每次循环都把命令放入后台运行
#一旦放入后台,就意味着{}里面的命令交给操作系统的一个线程处理了
#循环了1000次,就有1000个&把任务放入后台,操作系统会并发1000个线程来处理
#这些任务
done
wait #wait命令的意思是,等待(wait命令)上面的命令(放入后台的)都执行完毕了再
#往下执行。
#在这里写wait是因为,一条命令一旦被放入后台后,这条任务就交给了操作系统
#shell脚本会继续往下运行(也就是说:shell脚本里面一旦碰到&符号就只管把它
#前面的命令放入后台就算完成任务了,具体执行交给操作系统去做,脚本会继续
#往下执行),所以要在这个位置加上wait命令,等待操作系统执行完所有后台命令
end=`date +%s` #定义脚本运行的结束时间
echo "TIME:`exprend - $start`"
运行结果:
[root@iZ94yyzmpgvZ /]# . test1.sh
......
[989] Done { sleep 1; echo 'success'i; }
[990] Done { sleep 1; echo 'success'i; }
success992
[991] Done { sleep 1; echo 'success'i; }
[992] Done { sleep 1; echo 'success'i; }
success993
[993] Done { sleep 1; echo 'success'i; }
success994
success995
[994] Done { sleep 1; echo 'success'i; }
success996
[995] Done { sleep 1; echo 'success'i; }
[996] Done { sleep 1; echo 'success'i; }
success997
success998
[997] Done { sleep 1; echo 'success'i; }
success999
[998] Done { sleep 1; echo 'success'i; }
[999]- Done { sleep 1; echo 'success'i; }
success1000
[1000]+ Done { sleep 1; echo 'success'i; }
TIME:2
代码解析以及问题:
shell中实现并发,就是把循环体的命令用&符号放入后台运行,1000个任务就会并发1000个线程,运行时间2s,比起方案一的1000s,已经非常快了。
可以看到输出结果success4 ...success3完全都是无序的,因为大家都是后台运行的,这时候就是cpu随机运行了,所以并没有什么顺序
这样写确实可以实现并发,然后,大家可以想象一下,1000个任务就要并发1000个线程,这样对操作系统造成的压力非常大,它会随着并发任务数的增多,操作系统处理速度会变慢甚至出现其他不稳定因素,就好比你在对nginx调优后,你认为你的nginx理论上最大可以支持1w并发了,实际上呢,你的系统会随着高并发压力会不断攀升,处理速度会越来越慢(你以为你扛着500斤的东西你还能跑的跟原来一样快吗)
- 方案三:
思路:基于方案二,使用linux管道文件特性制作队列,控制线程数目
知识储备:
一.管道文件
1:无名管道(ps aux | grep nginx)
2:有名管道(mkfifo /tmp/fd1)
有名管道特性:
1.cat /tmp/fd1(如果管道内容为空,则阻塞)
实验:
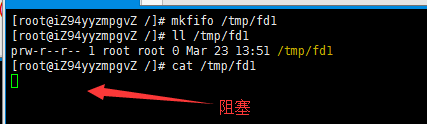
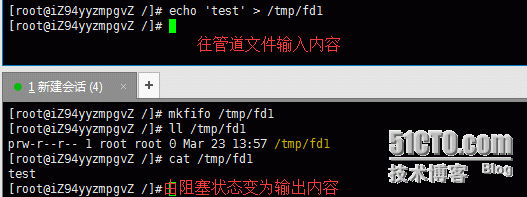
2.echo "test" > /tmp/fd1(如果没有读管道的操作,则阻塞)
总结:
利用有名管道的上述特性就可以实现一个队列控制了
你可以这样想:一个女士公共厕所总共就10个蹲位,这个蹲位就是队列长度,女厕
所门口放着10把药匙,要想上厕所必须拿一把药匙,上完厕所后归
还药匙,下一个人就可以拿药匙进去上厕所了,这样同时来了1千
位美女上厕所,那前十个人抢到药匙进去上厕所了,后面的990人
需要等一个人出来归还药匙才可以拿到药匙进去上厕所,这样10把
药匙就实现了控制1000人上厕所的任务(os中称之为信号量)
二.文件描述符
1.管道具有存一个读一个,读完一个就少一个,没有则阻塞,放回的可以重复取,这正是队列
特性,但是问题是当往管道文件里面放入一段内容,没人取则会阻塞,这样你永远也没办法
往管道里面同时放入10段内容(想当与10把药匙),解决这个问题的关键就是文件描述符了。
\2. mkfifo /tmp/fd1
创建有名管道文件exec 3<>/tmp/fd1,创建文件描述符3关联管道文件,这时候3这个文件描述符就拥有了管道的所有特性,还具有一个管道不具有的特性:无限存不阻塞,无限取不阻塞,而不用关心管道内是否为空,也不用关心是否有内容写入引用文件描述符: &3可以执行n次echo >&3 往管道里放入n把钥匙
exec命令用法:http://blog.sina.com.cn/s/blog_7099ca0b0100nby8.html
实现:
#!/bin/bash
start_time=`date +%s` #定义脚本运行的开始时间
[ -e /tmp/fd1 ] || mkfifo /tmp/fd1 #创建有名管道
exec 3<>/tmp/fd1 #创建文件描述符,以可读(<)可写(>)的方式关联管道文件,这时候文件描述符3就有了有名管道文件的所有特性
rm -rf /tmp/fd1 #关联后的文件描述符拥有管道文件的所有特性,所以这时候管道文件可以删除,我们留下文件描述符来用就可以了
for ((i=1;i<=10;i++))
do
echo >&3 #&3代表引用文件描述符3,这条命令代表往管道里面放入了一个"令牌"
done
for ((i=1;i<=1000;i++))
do
read -u3 #代表从管道中读取一个令牌
{
sleep 1 #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'i echo >&3 #代表我这一次命令执行到最后,把令牌放回管道
}&
done
wait
stop_time=`date +%s` #定义脚本运行的结束时间
echo "TIME:`exprstop_time - $start_time`"
exec 3<&- #关闭文件描述符的读
exec 3>&- #关闭文件描述符的写
运行结果:
[root@iZ94yyzmpgvZ /]# . test2.sh
success4
success6
success7
success8
success9
success5
......
success935
success941
success942
......
success992
[992] Done { sleep 1; echo 'success'i; echo 1>&3; }
success993
[993] Done { sleep 1; echo 'success'i; echo 1>&3; }
success994
[994] Done { sleep 1; echo 'success'i; echo 1>&3; }
success998
success999
success1000
success997
success995
success996
[995] Done { sleep 1; echo 'success'i; echo 1>&3; }
TIME:101
代码解析以及问题:
两个for循环,第一个for循环10次,相当于在女士公共厕所门口放了10把钥匙,第二个for
循环1000次,相当于1000个人来上厕所,read -u3相当于取走一把药匙,{}里面最后一行代码echo >&3相当于上完厕所送还药匙。
这样就实现了10把药匙控制1000个任务的运行,运行时间为101s,肯定不如方案二快,但是比方案一已经快很多了,这就是队列控制同一时间只有最多10个线程的并发,既提高了效率,又实现了并发控制。
注意:创建一个文件描述符exec 3<>/tmp/fd1 不能有空格,代表文件描述符3有可读(<)可写(>)权限,注意,打开的时候可以写在一起,关闭的时候必须分开关,exec 3<&-关闭读,exec 3>&-关闭写
想一下:
1.假如一台优化后的nginx单机可以接受最大的并发是1w,那么同时来了2w人,那nginx是怎么做的
2.或者,一家餐厅有10个服务员,餐厅的资金的支持它最多可以再招收90个服务员(apache可设置默认开始10个进程,最大可开启100个进程),也就是说这家餐厅最多可以有100个服务员。那现在同时有1000个人来吃饭,这时候会出现的现象是:前10个人会立马有人招待吃饭,然后餐厅每招收一个新服务员就有一个人可以坐下来吃饭,好,假设现在总共有100个服务员在提供服务了,那么还剩下900人如何处理,很简单,吃完一个滚一个,滚一个就进来一个吃饭。这样就实现了100个服务员去为1000个人提供服务。
实际上就是用一个100人的队列去控制1000个任务的运行,同一时间最多并发100个线程,这样既节省了系统资源又提高了效率





