存储引擎及日志深入详解

一、存储引擎
1. mysql的存储引擎
01)InnoDB
适合数据增删改查
02)MyISAM
存储一些只读的数据
03)MEMORY
支持hash索引
04)ARCHIVE
05)FEDERATED
06)EXAMPLE
07)BLACKHOLE
08)MERGE
09)NDBCLUSTER
10)CSV
#还可以使用第三方存储引擎:
MySQL当中插件式的存储引擎类型
MySQL的两个分支:
1.perconaDB
2.mariaDB
#查看存储引擎
mysql> show engines;
2. innodb和myisam的区别
#MyISAM:
不支持事务,但是每次查询都是原子的;
支持表级锁,即每次操作是对整个表加锁;
物理文件有三个
不支持热备
#InnoDb:
支持MVCC多事物并发控制
支持ACID的事务,支持事务的四种隔离级别;
支持行级锁:因此可以支持写并发;
物理文件有两个
支持热备
支持自动故障恢复
多缓冲区池
支持外键(不推荐使用)
#myisam存储引擎
-rw-rw---- 1 mysql mysql 10684 7月 9 15:10 user.frm #表结构
-rw-rw---- 1 mysql mysql 980 7月 15 09:14 user.MYD #数据文件
-rw-rw---- 1 mysql mysql 2048 7月 15 09:28 user.MYI #索引文件
#innodb存储引擎
-rw-rw---- 1 mysql mysql 8710 7月 17 10:59 city.frm #表结构
-rw-rw---- 1 mysql mysql 950272 7月 17 10:59 city.ibd #表空间(数据和索引)
#查看时用strings
[root@db03 ~]# strings /usr/local/mysql/data/world/stu.frm
------------------------------------------------------
# innodb核心特性
MVCC:一种并发控制的方法,在数据库管理系统中,实现对数据库的并发访问;
支持事务
行级锁 #innodb支持行级锁,myiasm支持表级锁
热备份 #innodb支持热备,myisam不支持热备
自动故障恢复 Crash Safe Recovery
3. 存储引擎相关命令
1)查看当前数据库的存储引擎
mysql> SELECT @@default_storage_engine;
+--------------------------+
| @@default_storage_engine |
+--------------------------+
| InnoDB |
+--------------------------+
1 row in set (0.00 sec)
2)查看表的存储引擎
mysql> use information_schema
#查看哪些表是innodb存储引擎
mysql> select TABLE_SCHEMA,TABLE_Name,ENGINE from tables where ENGINE='innodb';
#查看哪些表时myisam存储引擎
mysql> select TABLE_SCHEMA,TABLE_Name,ENGINE from tables where ENGINE='myisam';
#查看表信息
mysql> select * from information_schema.tables where table_name='test11'\G
#查看指定表的存储引擎
mysql> show create table city;
#查看列信息
mysql> select * from COLUMNS where COLUMN_NAME='name'\G
3)修改存储引擎
#临时设置
mysql> set @@default_storage_engine=myisam;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @@default_storage_engine;
+--------------------------+
| @@default_storage_engine |
+--------------------------+
| MyISAM |
+--------------------------+
#永久修改
[root@db03 mysql]# vim /etc/my.cnf
[mysqld]
default_storage_engine=myisam
#建表时指定存储引擎
mysql> create table innodb(id int) ENGINE=innodb;
4. Innodb 存储引擎

- 核心特性



表空间介绍
5.5版本以后出现共享表空间概念
表空间的管理模式的出现是为了数据库的存储更容易扩展
5.6以后版本中默认的是独立表空间
# 查看表空间模式:
mysql> select @@innodb_file_per_table;
+-------------------------+
| @@innodb_file_per_table |
+-------------------------+
| 1 |
+-------------------------+
1代表独立表空间模式,0代表共享表空间模式.
5.5版本后都可以切换表空间模式.
mysql> set global innodb_file_per_table=1;
只对设置之后的新文件生效.
共享表空间(ibdata1)
1)# 存储的内容:
1.1 系统数据
1.2 undo undo log日志,事务日志
1.3 临时表
2)# 概念
2.1.优点:
可以将表空间分成多个文件存放到各个磁盘上(表空间文件大小不受表大小的限制,如一个表可以分布在不同的文件上)。
数据和文件放在一起方便管理。
2.2.缺点:
所有的数据和索引存放到一个文件中,虽然可以把一个大文件分成多个小文件,但是多个表及索引在表空间中混合存储,
这样对于一个表做了大量删除操作后表空间中将会有大量的空隙,特别是对于统计分析,日志系统这类应用最不适合用共享表空间。
3)# 配置共享表空间
[root@db03 data]# vim /etc/my.cnf
[mysqld]
innodb_data_file_path=ibdata1:76M;tmp/ibdata2:50M:autoextend
4)# 查看共享表空间
mysql> show variables like '%path%';
+----------------------------------+----------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------+
| innodb_data_file_path | ibdata1:76M;tmp/ibdata2:50M:autoextend |
独立表空间 *.ibd
1)# 概念
对于用户自主创建的表,会采用此种模式,每个表由一个独立的表空间进行管理
1.1.优点:
1)每个表都有自己独立的表空间
2)数据分开存储
1.2.缺点:
1)单表空间不能过大,不能大于100G
查看独立表空间
#物理查看
[root@db01 ~]# ll /application/mysql/data/world/
-rw-rw---- 1 mysql mysql 688128 Aug 14 16:23 city.ibd
#命令行查看是否开启独立表空间
mysql> show variables like '%per_table%';
innodb_file_per_table=ON
移除和导入表空间数据的命令
#1.移除表的表空间数据 (会物理删除city_new.ibd文件)
mysql> alter table city_new discard tablespace;
#2.表读取表空间数据(需要存在city_new.ibd文件)
mysql> alter table city_new import tablespace;
5. Innodb核心 - 事务
1.)什么是事务(transaction)?
主要针对DML语句(update,delete,insert)
1.一组数据操作执行步骤,这些步骤被视为一个工作单元:
1)用于对多个语句进行分组
2)可以在多个客户机并发访问同一个表中的数据时使用
2.所有步骤都成功或都失败
1)如果所有步骤正常,则执行
2)如果步骤出现错误或不完整,则取消
2.)事务的演示
# 首先改变mysql的提交模式
set autocommit=0; 禁止自动提交
set autocommit=1; 开启自动提交
1)成功事务
mysql> create table stu(id int,name varchar(10),sex enum('f','m'),money int);
mysql> begin;
mysql> insert into stu(id,name,sex,money) values(1,'zhang3','m',100), (2,'zhang4','m',110);
mysql> commit;
2)事务回滚
mysql> begin;
mysql> update stu set name='zhang3';
mysql> delete from stu;
mysql> rollback;
'!注意!只针对DML语句,对于删除库表等其他语句无效。'
3.)事务的特性(ACID)
#Atomic(原子性)
所有语句作为一个单元全部成功执行或全部取消。
#Consistent(一致性)
如果数据库在事务开始时处于一致状态,则在执行该。事务期间将保留一致状态。
#Isolated(隔离性)
事务之间不相互影响。
#Durable(持久性)
事务成功完成后,所做的所有更改都会准确地记录在数据库中。所做的更改不会丢失。

4.)事务的控制语句
START TRANSACTION(或 BEGIN): # 显式开始一个新事务
SAVEPOINT: # 分配事务过程中的一个位置,以供将来引用
'存储点可以设置多个,命令为: savepoint 位置点名 '
COMMIT: # 永久记录当前事务所做的更改
ROLLBACK: # 取消当前事务所做的更改
ROLLBACK TO SAVEPOINT: # 取消在 savepoint 之后执行的更改
RELEASE SAVEPOINT: # 删除 savepoint 标识符
SET AUTOCOMMIT: # 为当前连接禁用或启用默认 autocommit 模式
5.)事务的自动提交
#临时设置关闭
mysql> set autocommit=0;
Query OK, 0 rows affected (0.02 sec)
#永久设置关闭
[root@db01 world]# vim /etc/my.cnf
[mysqld]
autocommit=0
6. 事务的日志
1.)redo log

# 物理文件存放于ib_logfile0,ib_logfile1名称存在
'文字描述流程'
#修改
1)begin语句开始后,首先将表中命令id=1的行所在数据页加载到内存中data buffer page
2)MySQL实例在内存中将id=1的数据页改成id=2
3)id=1变成id=2的变化过程会记录到,redo内存区域,也就是redo buffer page中
4)当敲下commit命令的瞬间,MySQL会将redo buffer page写入磁盘区域redo log
5)当写入成功之后,commit返回ok
#查询
1.首先将表中id=1的行所在数据页加载到内存中data buffer page
2.将redo log中id=1变成id=2的变化过程取加载到redo buffer page
3.通过data buffer page和redo buffer page得到一个结果

2.)undo log

# 物理文件存于ibdata1,ibdata2
1)作用
undo,顾名思义“回滚日志”,是事务日志的一种
在事务ACID过程中,实现的是“A”原子性的作用。当然CI的特性也和undo有关
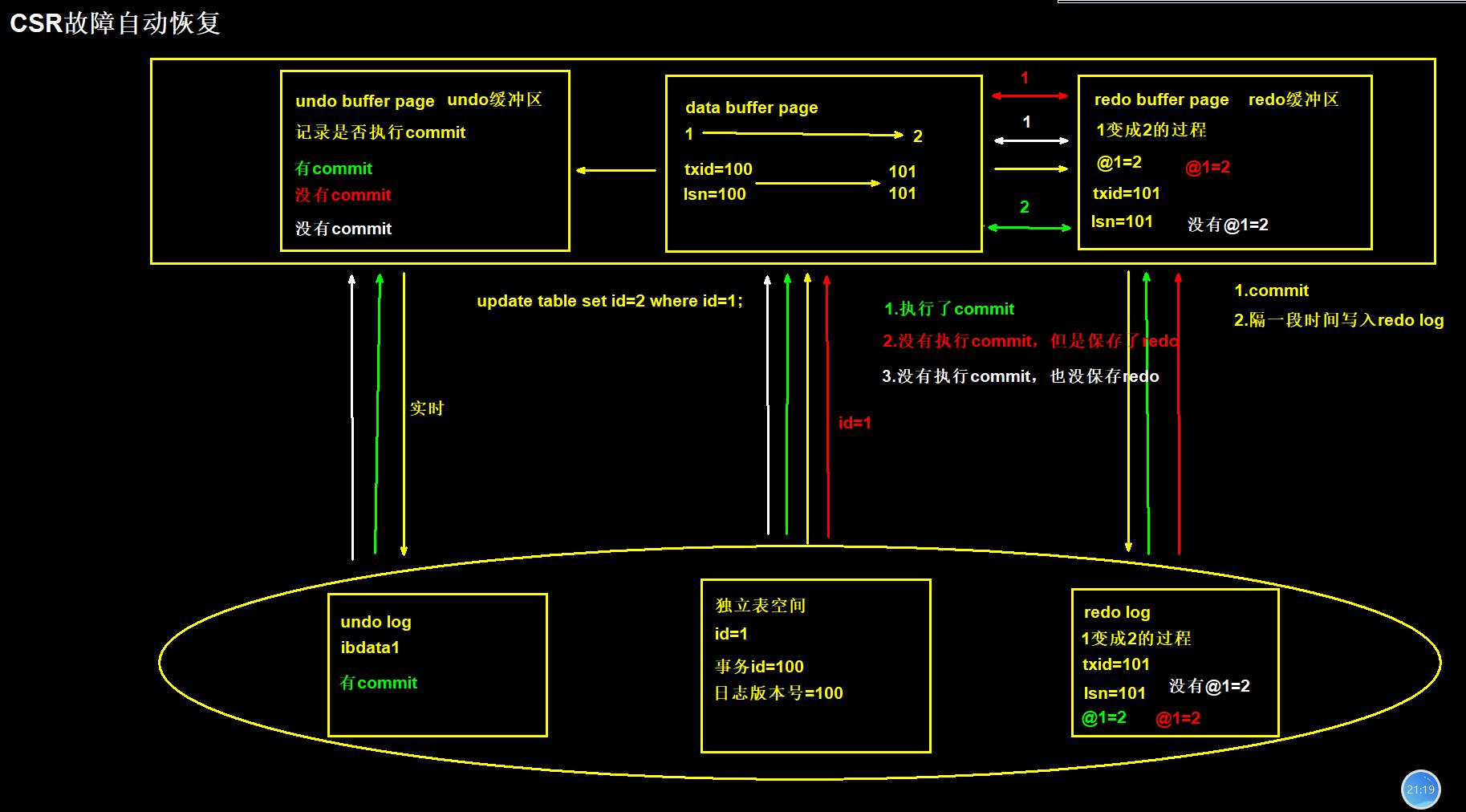
3.)redo和undo的存储位置
#redo位置
[root@db01 data]# ll /application/mysql/data/
-rw-rw---- 1 mysql mysql 50331648 Aug 15 06:34 ib_logfile0
-rw-rw---- 1 mysql mysql 50331648 Mar 6 2017 ib_logfile1
#undo位置
[root@db01 data]# ll /application/mysql/data/
-rw-rw---- 1 mysql mysql 79691776 Aug 15 06:34 ibdata1
-rw-rw---- 1 mysql mysql 79691776 Aug 15 06:34 ibdata2
4.)redo log、undo log和二进制日志bin log的区别
1.redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
2.undo用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录。
当事务提交的时候,innodb不会立即删除undo log,因为后续还可能会用到undo log,如隔离级别为repeatable read时,事务读取的都是开启事务时的最新提交行版本,只要该事务不结束,该行版本就不能删除,即undo log不能删除。
但是在事务提交的时候,会将该事务对应的undo log放入到删除列表中,未来通过purge来删除。并且提交事务时,还会判断undo log分配的页是否可以重用,如果可以重用,则会分配给后面来的事务,避免为每个独立的事务分配独立的undo log页而浪费存储空间和性能。
通过undo log记录delete和update操作的结果发现:(insert操作无需分析,就是插入行而已)
delete操作实际上不会直接删除,而是将delete对象打上delete flag,标记为删除,最终的删除操作是purge线程完成的。
update分为两种情况:update的列是否是主键列。
如果不是主键列,在undo log中直接反向记录是如何update的。即update是直接进行的。
如果是主键列,update分两部执行:先删除该行,再插入一行目标行。
7. 事务中的锁
1.什么是锁
“锁”顾名思义就是锁定的意思。
2.作用
在事务ACID特性过程中,“锁”和“隔离级别”一起来实现“I”隔离性的作用。
3.锁的类别
排他锁:保证在多事务操作时,数据的一致性。(在我修改数据时,其他人不得修改)
共享锁:保证在多事务工作期间,数据查询时不会被阻塞。
乐观锁:多实务操作时,数据可以同时修改,谁先提交,以谁为准
悲观锁:多实务操作时,数据只有一个人可以修改
4.多版本并发控制
1.) 只阻塞修改类操作(排他锁),不阻塞查询类操作(共享锁)
2.) 乐观锁的机制(谁先提交谁为准)
5.锁的粒度
1.) MyIsam:表级锁
2.) Innodb:行级锁
8. 事务中的隔离级别
1.)四种隔离级别
1.RU级别:READ UNCOMMITTED(独立提交):未提交读,允许事务查看其他事务所进行的未提交更改
2.RC级别:READ COMMITTED:允许事务查看其他事务所进行的已提交更改,查看不需要重新记入数据库
3.RR级别:REPEATABLE READ:允许事务查看其他事务所进行的已提交更改,查看数据需要重新进入数据库(InnoDB 的默认级别)
4.串行化:SERIALIZABLE:将一个事务的结果与其他事务完全隔离
2.)查看隔离级别
#查看隔离级别
mysql> show variables like '%iso%';
3.)设置隔离级别
1)设置RU级别
[root@db03 ~]# vim /etc/my.cnf
transaction_isolation=read-uncommit
2)设置RC级别
[root@db03 ~]# vim /etc/my.cnf
transaction_isolation=read-commit
4.)名词
1.脏读:RU级别,执行事务修改数据,被读取,但是数据最终回滚了,查询到的数据就是脏读
2.幻读:删除所有表数据,删除的同时有人插入数据,查看数据时以为是没删干净
3.不可重复读:修改数据后被读取,被读取之后再次修改数据,两次数据不一致
5.)如何解决脏读,幻读,不可重复读的问题?
1.RU:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
2.RC:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
3.RR:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
4.串行化:最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
二、经典实际生产故障案例及解决
1.故障

2.解决方案和步骤



# 报错注意: import导入的数据ibd文件需要授权mysql.mysql权限后才能导入.
三、InnoDB关键特性之double write
两次写的原理机制
1、解决问题
2、使用场景
3、doublewrite的工作流程
4、崩溃恢复
1.脏页刷盘风险
关于IO的最小单位:
1、数据库IO的最小单位是16K(MySQL默认,oracle是8K)
2、文件系统IO的最小单位是4K(也有1K的)
3、磁盘IO的最小单位是512字节
因此,存在IO写入导致page损坏的风险:

2.doublewrite:两次写
提高innodb的可靠性,用来解决部分写失败(partial page write页断裂)。
1、Double write解决了什么问题
一个数据页的大小是16K,假设在把内存中的脏页写到数据库的时候,写了2K突然掉电,也就是说前2K数据是新的,后14K是旧的,那么磁盘数据库这个数据页就是不完整的,是一个坏掉的数据页。redo只能加上旧、校检完整的数据页恢复一个脏块,不能修复坏掉的数据页,所以这个数据就丢失了,可能会造成数据不一致,所以需要double write。
2、使用情景
当数据库正在从内存想磁盘写一个数据页是,数据库宕机,从而导致这个页只写了部分数据,这就是部分写失效,它会导致数据丢失。这时是无法通过重做日志恢复的,因为重做日志记录的是对页的物理修改,如果页本身已经损坏,重做日志也无能为力。
3、double write工作流程

doublewrite由两部分组成,一部分为内存中的doublewrite buffer,其大小为2MB,另一部分是磁盘上共享表空间(ibdata x)中连续的128个页,即2个区(extent),大小也是2M。
1)当一系列机制触发数据缓冲池中的脏页刷新时,并不直接写入磁盘数据文件中,而是先拷贝至内存中的doublewrite buffer中;
2)接着从两次写缓冲区分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB;
3)待第二步完成后,再将doublewrite buffer中的脏页数据写入实际的各个表空间文件(离散写);(脏页数据固化后,即进行标记对应doublewrite数据可覆盖)
4、doublewrite的崩溃恢复
如果操作系统在将页写入磁盘的过程中发生崩溃,在恢复过程中,innodb存储引擎可以从共享表空间的doublewrite中找到该页的一个最近的副本,将其复制到表空间文件,再应用redo log,就完成了恢复过程。
因为有副本所以也不担心表空间中数据页是否损坏。
Q:为什么log write不需要doublewrite的支持?
A:
因为redolog写入的单位就是512字节,也就是磁盘IO的最小单位,所以无所谓数据损坏。
3.doublewrite的副作用
1、double write带来的写负载
1)double write是一个buffer, 但其实它是开在物理文件上的一个buffer, 其实也就是file, 所以它会导致系统有更多的fsync操作, 而硬盘的fsync性能是很慢的, 所以它会降低mysql的整体性能。
2)但是,doublewrite buffer写入磁盘共享表空间这个过程是连续存储,是顺序写,性能非常高,(约占写的%10),牺牲一点写性能来保证数据页的完整还是很有必要的。
2、监控double write工作负载
mysql> show global status like '%dblwr%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Innodb_dblwr_pages_written | 7 |
| Innodb_dblwr_writes | 3 |
+----------------------------+-------+
关注点:Innodb_dblwr_pages_written / Innodb_dblwr_writes
开启doublewrite后,每次脏页刷新必须要先写doublewrite,而doublewrite存在于磁盘上的是两个连续的区,每个区由连续的页组成,一般情况下一个区最多有64个页,所以一次IO写入应该可以最多写64个页。
而根据以上系统Innodb_dblwr_pages_written与Innodb_dblwr_writes的比例来看,大概在3左右,远远还没到64(如果约等于64,那么说明系统的写压力非常大,有大量的脏页要往磁盘上写),所以从这个角度也可以看出,系统写入压力并不高。
3、关闭double write适合的场景
1、海量DML
2、不惧怕数据损坏和丢失
3、系统写负载成为主要负载
mysql> show variables like '%double%';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| innodb_doublewrite | ON |
+--------------------+-------+
作为InnoDB的一个关键特性,doublewrite功能默认是开启的,但是在上述特殊的一些场景也可以视情况关闭,来提高数据库写性能。静态参数,配置文件修改,重启数据库。
4、为什么没有把double write里面的数据写到data page里面呢?
1)double write里面的数据是连续的,如果直接写到data page里面,而data page的页又是离散的,写入会很慢。
2)double write里面的数据没有办法被及时的覆盖掉,导致double write的压力很大;短时间内可能会出现double write溢出的情况。





