从诗词大会到elasticsearch原理解析(转)到入门操作(转)

1. Elasticsearch原理解析
作者是阿里的技术专家,把技术解释的通俗易懂,太牛了。该文转自作者的个人公众号:互联网侦察,里面有很多系列文章,
关于算法,大数据,面试现场三个系列,通过漫画学到知识,太棒了
原文:https://mp.weixin.qq.com/s/LD2VG6dRNYXOO9KE38F_Mg
作者:channingbreeze
公众号:互联网侦察
小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了。

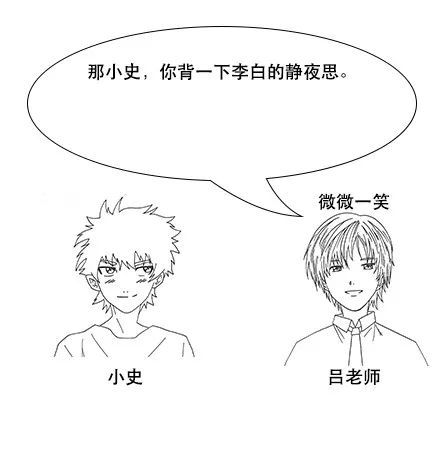
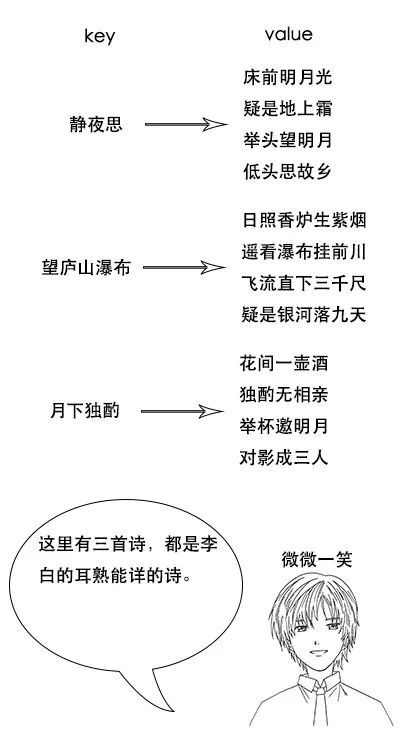
随着央视诗词大会的热播,小史开始对诗词感兴趣,最喜欢的就是飞花令的环节。
但是由于小史很久没有背过诗词了,飞一个字很难说出一句,很多之前很熟悉的诗句也想不起来。





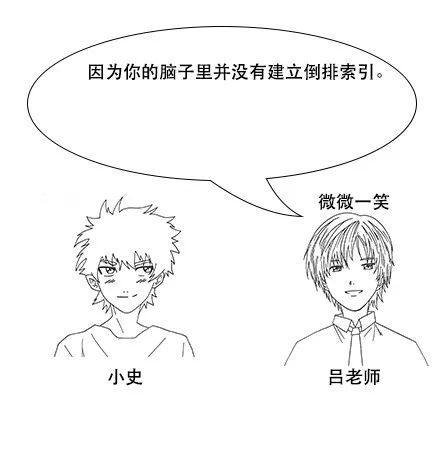

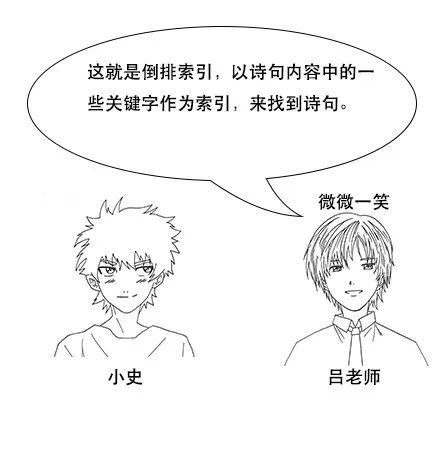
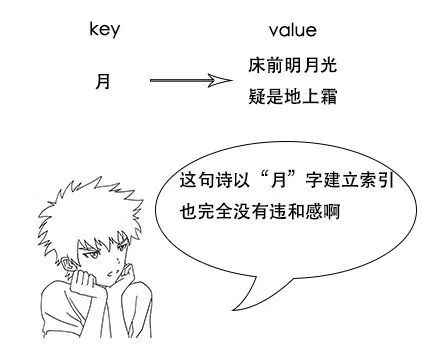
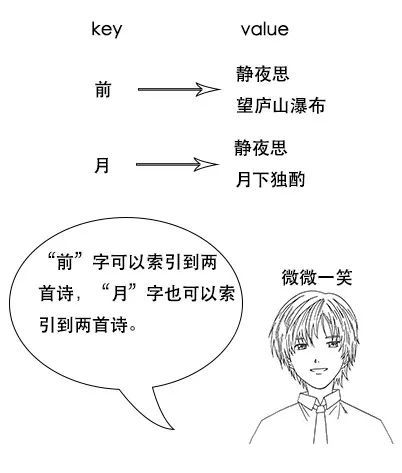
【倒排索引】
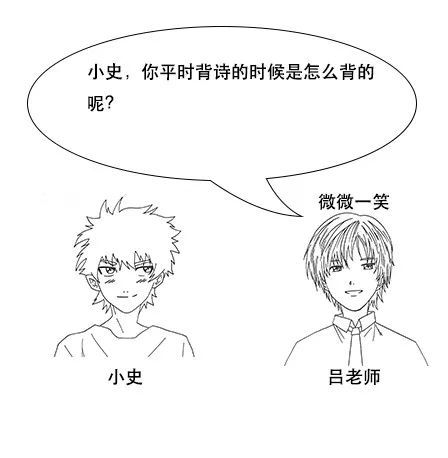




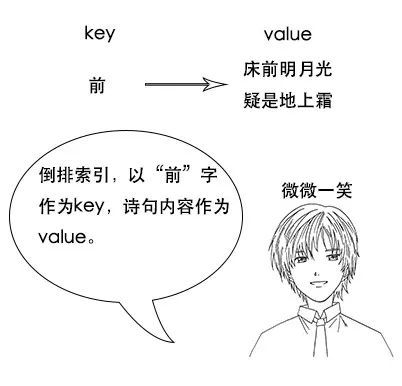
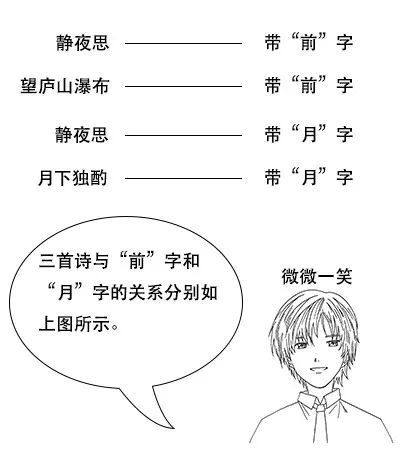
吕老师:但是我让你说出带“前”字的诗句,由于没有索引,你只能遍历脑海中所有诗词,当你的脑海中诗词量大的时候,就很难在短时间内得到结果了。





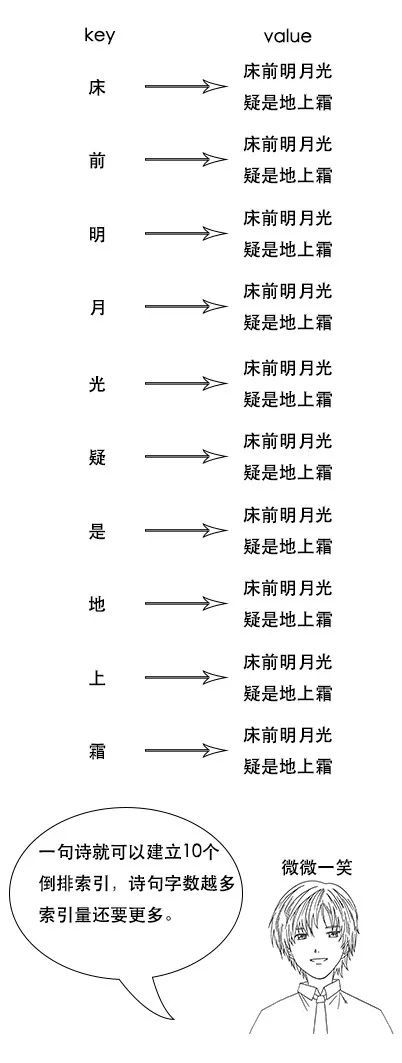
【索引量爆炸】








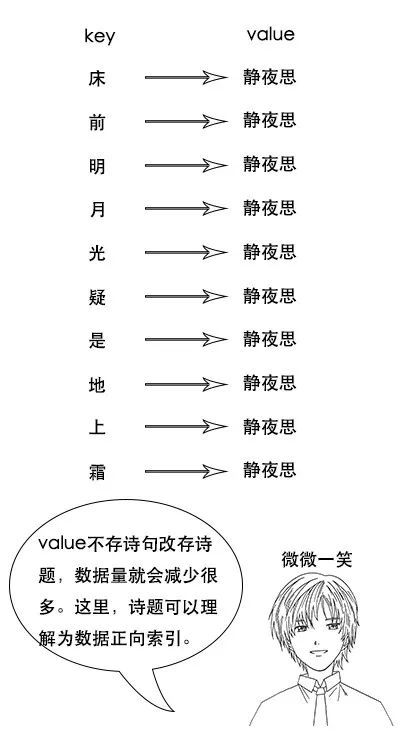




【搜索引擎原理】











【elasticsearch简介】





吕老师:但是lucene还是一个库,必须要懂一点搜索引擎原理的人才能用的好,所以后来又有人基于lucene进行封装,写出了elasticsearch。





【elasticsearch基本概念】





吕老师:类型是用来定义数据结构的,你可以认为是mysql中的一张表。文档就是最终的数据了,你可以认为一个文档就是一条记录。
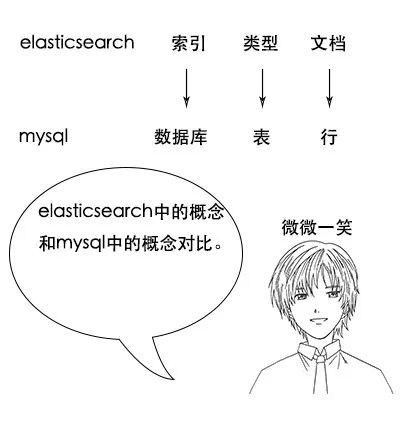


吕老师:比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫poems的索引,然后创建一个名叫poem的类型,类型是通过mapping来定义每个字段的类型,比如诗题、作者、朝代都是keyword类型,诗内容是text类型,而字数是integer类型,最后就是把数据组织成json格式存放进去了。


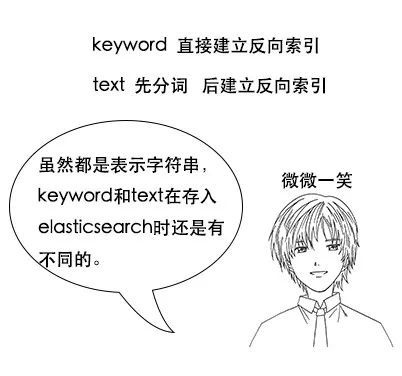
吕老师:这个问题问得好,这涉及到分词的问题,keyword类型是不会分词的,直接根据字符串内容建立反向索引,text类型在存入elasticsearch的时候,会先分词,然后根据分词后的内容建立反向索引。


吕老师:之前我们说过,elasticsearch把操作都封装成了http的api,我们只要给elasticsearch发送http请求就行。比如使用curl -XPUT 'http://ip:port/poems',就能建立一个名为poems的索引,其他操作也是类似的。

【elasticsearch分布式原理】


吕老师:没错,elasticsearch也是会对数据进行切分,同时每一个分片会保存多个副本,其原因和hdfs是一样的,都是为了保证分布式环境下的高可用。
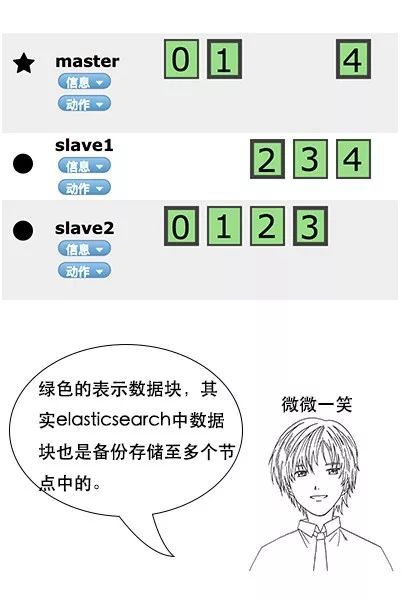


吕老师:没错,在elasticsearch中,节点是对等的,节点间会通过自己的一些规则选取集群的master,master会负责集群状态信息的改变,并同步给其他节点。

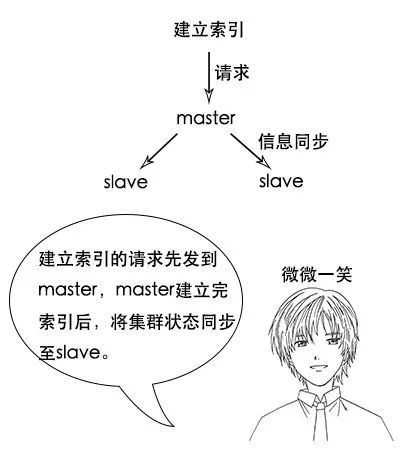

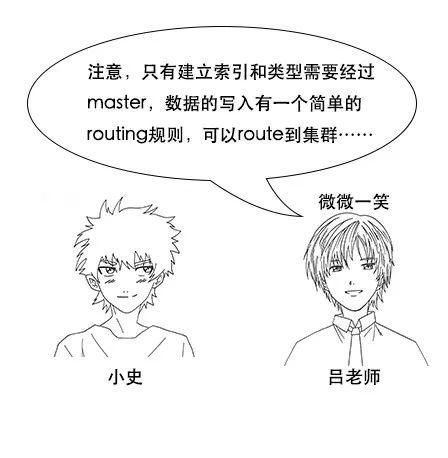
吕老师:注意,只有建立索引和类型需要经过master,数据的写入有一个简单的routing规则,可以route到集群中的任意节点,所以数据写入压力是分散在整个集群的。

【elk系统】


吕老师:其实很多公司都用elasticsearch搭建elk系统,也就是日志分析系统。其中e就是elasticsearch,l是logstash,是一个日志收集系统,k是kibana,是一个数据可视化平台。
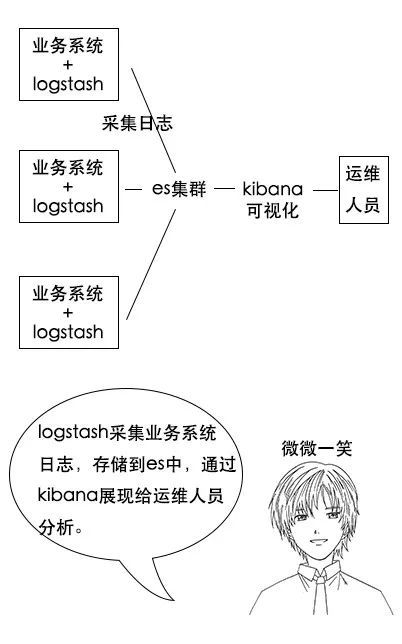

吕老师:分析日志的用处可大了,你想,假如一个分布式系统有1000台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,是不是非常麻烦?


吕老师:但是如果日志接入了elk系统就不一样。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入elk系统中,我们直接在kibana就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。


【笔记】
小史学完了elasticsearch,在笔记本上写下了如下记录:
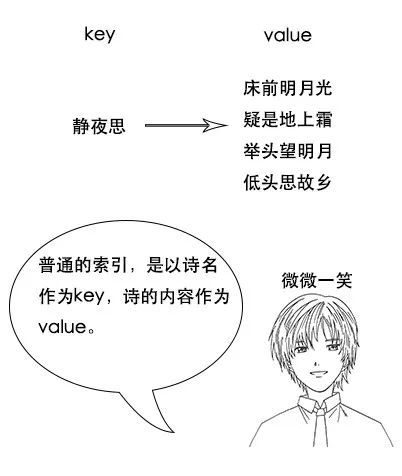
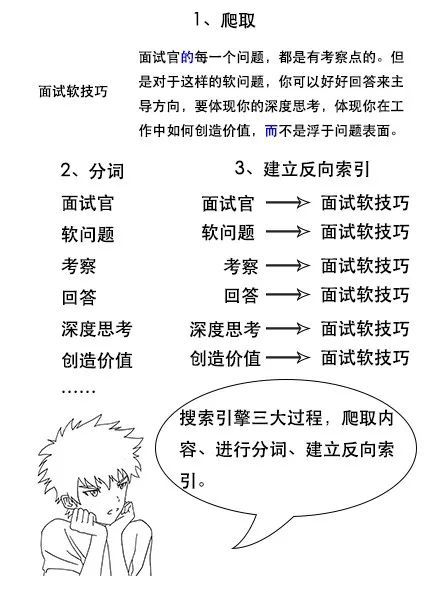
1、反向索引又叫倒排索引,是根据文章内容中的关键字建立索引
2、搜索引擎原理就是建立反向索引
3、elasticsearch在lucene的基础上进行封装,实现了分布式搜索引擎
4、elasticsearch中的索引、类型和文档的概念比较重要,类似于mysql中的数据库、表和行
5、elasticsearch也是master-slave架构,也实现了数据的分片和备份
6、elasticsearch一个典型应用就是elk日志分析系统
写完,又高高兴兴背诗去了。
观书有感
朱熹
半亩方塘一鉴开,天光云影共徘徊。
问渠那得清如许?为有源头活水来。
2. Elasticsearch入门
Elasticsearch提供了多种交互使用方式,包括Java API和RESTful API ,本文主要介绍RESTful API 。所有其他语言可以使用RESTful API 通过端口 9200 和 Elasticsearch 进行通信,你可以用你最喜爱的 web 客户端访问 Elasticsearch 。甚至,你还可以使用 curl 命令来和 Elasticsearch 交互。
一个Elasticsearch请求和任何 HTTP 请求一样,都由若干相同的部件组成:
curl -X '://:/?' -d ''
返回的数据格式为JSON,因为Elasticsearch中的文档以JSON格式储存。其中,被 < > 标记的部件:
| 部件 | 说明 |
|---|---|
| VERB | 适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE。 |
| PROTOCOL | http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理) |
| HOST | Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
| PORT | 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
| PATH | API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
| QUERY_STRING | 任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
| BODY | 一个 JSON 格式的请求体 (如果请求需要的话) |
对于HTTP方法,它们的具体作用为:
| HTTP方法 | 说明 |
|---|---|
| GET | 获取请求对象的当前状态 |
| POST | 改变对象的当前状态 |
| PUT | 创建一个对象 |
| DELETE | 销毁对象 |
| HEAD | 请求获取对象的基础信息 |
我们以下面的数据为例,来展示Elasticsearch的用法。

以下全部的操作都在Kibana中完成,创建的index为conference, type为event .
插入数据
首先创建index为conference, 创建type为event, 插入id为1的第一条数据,只需运行下面命令就行:
PUT /conference/event/1
{
"host": "Dave",
"title": "Elasticsearch at Rangespan and Exonar",
"description": "Representatives from Rangespan and Exonar will come and discuss how they use Elasticsearch",
"attendees": ["Dave", "Andrew", "David", "Clint"],
"date": "2013-06-24T18:30",
"reviews": 3
}
在上面的命令中,路径/conference/event/1表示文档的index为conference, type为event, id为1. 类似于上面的操作,依次插入剩余的4条数据,完成插入后,查看数据如下:

插入数据
删除数据
比如我们想要删除conference中event里面id为5的数据,只需运行下面命令即可:
DELETE /conference/event/5
返回结果如下:
{
"_index" : "conference",
"_type" : "event",
"_id" : "5",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
表示该文档已成功删除。如果想删除整个event类型,可输入命令:
DELETE /conference/event
如果想删除整个conference索引,可输入命令:
DELETE /conference
修改数据
修改数据的命令为POST, 比如我们想要将conference中event里面id为4的文档的作者改为Bob,那么需要运行命令如下:
POST /conference/event/4/_update
{
"doc": {"host": "Bob"}
}
返回的信息如下:(表示修改数据成功)
{
"_index" : "conference",
"_type" : "event",
"_id" : "4",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 7,
"_primary_term" : 1
}
查看修改后的数据如下:

修改数据
查询数据
查询数据的命令为GET,查询命令也是Elasticsearch最为重要的功能之一。比如我们想查询conference中event里面id为1的数据,运行命令如下:
GET /conference/event/1
返回的结果如下:
{
"_index" : "conference",
"_type" : "event",
"_id" : "1",
"_version" : 2,
"found" : true,
"_source" : {
"host" : "Dave",
"title" : "Elasticsearch at Rangespan and Exonar",
"description" : "Representatives from Rangespan and Exonar will come and discuss how they use Elasticsearch",
"attendees" : [
"Dave",
"Andrew",
"David",
"Clint"
],
"date" : "2013-06-24T18:30",
"reviews" : 3
}
}
在_source 属性中,内容是原始的 JSON 文档,还包含有其它属性,比如_index, _type, _id, _found等。
如果想要搜索conference中event里面所有的文档,运行命令如下:
GET /conference/event/_search
返回结果包括了所有四个文档,放在数组 hits 中。
当然,Elasticsearch 提供更加丰富灵活的查询语言叫做 查询表达式 , 它支持构建更加复杂和健壮的查询。利用查询表达式,我们可以检索出conference中event里面所有host为Bob的文档,命令如下:
GET /conference/event/_search
{
"query" : {
"match" : {
"host" : "Bob"
}
}
}
返回的结果只包括了一个文档,放在数组 hits 中。
接着,让我们尝试稍微高级点儿的全文搜索——一项传统数据库确实很难搞定的任务。搜索下所有description中含有"use Elasticsearch"的event:
GET /conference/event/_search
{
"query" : {
"match" : {
"description" : "use Elasticsearch"
}
}
}
返回的结果(部分)如下:
{
...
"hits" : {
"total" : 2,
"max_score" : 0.65109104,
"hits" : [
{
...
"_score" : 0.65109104,
"_source" : {
"host" : "Dave Nolan",
"title" : "real-time Elasticsearch",
"description" : "We will discuss using Elasticsearch to index data in real time",
...
}
},
{
...
"_score" : 0.5753642,
"_source" : {
"host" : "Dave",
"title" : "Elasticsearch at Rangespan and Exonar",
"description" : "Representatives from Rangespan and Exonar will come and discuss how they use Elasticsearch",
...
}
}
]
}
}
返回的结果包含了两个文档,放在数组 hits 中。让我们对这个结果做一些分析,第一个文档的description里面含有“using Elasticsearch”,这个能匹配“use Elasticsearch”是因为Elasticsearch含有内置的词干提取算法,之后两个文档按_score进行排序,_score字段表示文档的相似度(默认的相似度算法为BM25)。
如果想搜索下所有description中严格含有"use Elasticsearch"这个短语的event,可以使用下面的命令:
GET /conference/event/_search
{
"query" : {
"match_phrase": {
"description" : "use Elasticsearch"
}
}
}
这时候返回的结果只有一个文档,就是上面输出的第二个文档。
作者:山阴少年
链接:https://www.jianshu.com/p/d48c32423789
来源:简书





