Tidb优势和架构、部署、集群及组件管理

一、Tidb数据库优势和架构
1.TiDB优势
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
2.Tidb架构
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:
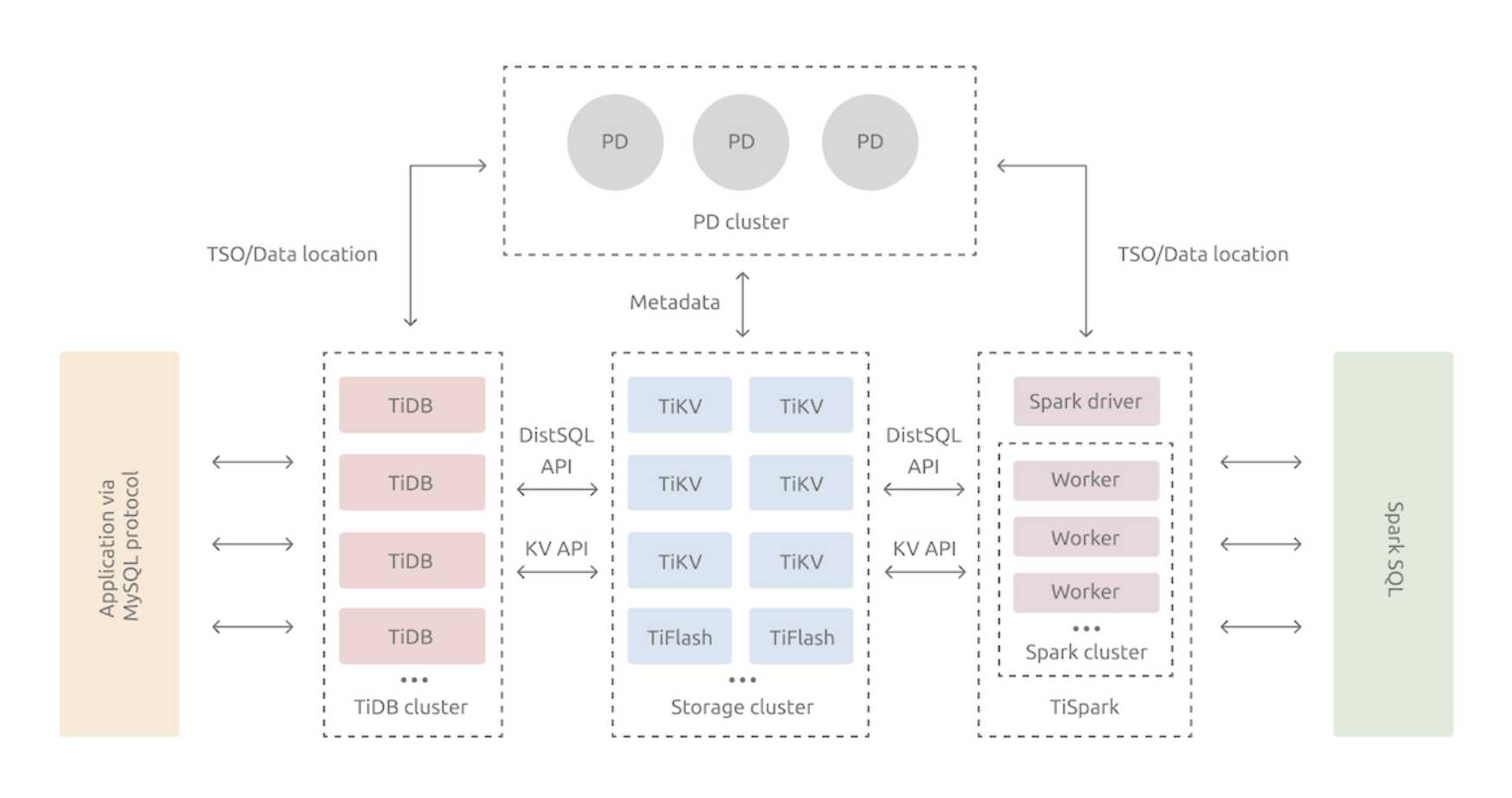
- TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
- 存储节点TiKV、TiFlash
- TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
二、Tidb部署
TiUP 是在物理机或虚拟机上的 TiDB 包管理器,管理着 TiDB 的众多的组件,如 TiDB、PD、TiKV 等。当你想要运行 TiDB 生态中任何组件时,只需要执行一行 TiUP 命令即可。
TiUP cluster 是 TiUP 提供的使用 Golang 编写的集群管理组件,通过 TiUP cluster 组件就可以进行日常的运维工作,包括部署、启动、关闭、销毁、弹性扩缩容、升级 TiDB 集群,以及管理 TiDB 集群参数。
1.环境准备
- 内存不足会导致服务无法启动,注意内存既磁盘大小;
-
TiDB 运行需要有足够的内存。如果内存不足,不建议使用 swap 作为内存不足的缓冲,因为这会降低性能。建议永久关闭系统 swap。
要永久关闭 swap,可执行以如下命令:
echo "vm.swappiness = 0">> /etc/sysctl.conf
swapoff -a && swapon -a
sysctl -p
- 具体环境配置参考:
https://docs.pingcap.com/zh/tidb/stable/check-before-deployment
2.安装 TiUP
以普通用户身份登录中控机。以 tidb 用户为例,后续安装 TiUP 及集群管理操作均通过该用户完成:
1.执行如下命令安装 TiUP 工具:
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
2.按如下步骤设置 TiUP 环境变量:
source 路径/.bash_profile (会有提示)
3.确认 TiUP 工具是否安装:
which tiup
=========
/root/.tiup/bin/tiup
4.安装 TiUP cluster 组件:
tiup cluster
如果已经安装,则更新 TiUP cluster 组件至最新版本:
tiup update --self && tiup update cluster
预期输出 “Update successfully!” 字样。
5.验证当前 TiUP cluster 版本信息:
tiup --binary cluster
3.集群配置文件
根据不同的集群拓扑,编辑 TiUP 所需的集群初始化配置文件。可以通过 TiUP 工具在中控机上面创建 YAML 格式集群配置文件,例如 topology.yaml:
tiup cluster template > topology.yaml
# 注意
混合部署场景也可以使用 `tiup cluster template --full > topology.yaml` 生成的建议拓扑模板,
跨机房部署场景可以使用 `tiup cluster template --multi-dc > topology.yaml` 生成的建议拓扑模板。
#详细场景配置参考文档:https://docs.pingcap.com/zh/tidb/stable/production-deployment-using-tiup
执行 `vi topology.yaml`,按实际场景配置以下参数:
- 特别注意!!!
# ---------------特别注意--------------- #
1. 配置文件中的部分参数一旦生产就无法修改。
2. 'tiup cluster edit-config 集群名' 修改集群配置后必须使用'tiup cluster reload 集群名' 来重新载入配置。重启无效!!!
# ------------------------------------- #
- 配置模板
# # Global variables are applied to all deployments and used as the default value of the deployments if a specific deployment value is missing.不配置项目会使用默认参数
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidb-data"
# # Monitored variables are applied to all the machines.
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
# deploy_dir: "/tidb-deploy/monitored-9100"
# data_dir: "/tidb-data/monitored-9100"
# log_dir: "/tidb-deploy/monitored-9100/log"
server_configs:
tidb:
log.slow-threshold: 300
binlog.enable: true # 配置pump和drainer需开启
binlog.ignore-error: true # 配置pump和drainer需开启
tikv:
# server.grpc-concurrency: 4
# raftstore.apply-pool-size: 2
# raftstore.store-pool-size: 2
# rocksdb.max-sub-compactions: 1
# storage.block-cache.capacity: "16GB"
# readpool.unified.max-thread-count: 12
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
pd:
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
cdc:
# capture-session-ttl: 10
# sorter.sort-dir: "/tmp/cdc_sort"
pd_servers:
- host: 10.0.1.4
# ssh_port: 22
# name: "pd-1"
# client_port: 2379
# peer_port: 2380
# deploy_dir: "/tidb-deploy/pd-2379"
# data_dir: "/tidb-data/pd-2379"
# log_dir: "/tidb-deploy/pd-2379/log"
# numa_node: "0,1"
# # The following configs are used to overwrite the `server_configs.pd` values.
# config:
# schedule.max-merge-region-size: 20
# schedule.max-merge-region-keys: 200000
- host: 10.0.1.5
- host: 10.0.1.6
tidb_servers:
- host: 10.0.1.1
# ssh_port: 22
# port: 4000
# status_port: 10080
# deploy_dir: "/tidb-deploy/tidb-4000"
# log_dir: "/tidb-deploy/tidb-4000/log"
# numa_node: "0,1"
# # The following configs are used to overwrite the `server_configs.tidb` values.
# config:
# log.slow-query-file: tidb-slow-overwrited.log
- host: 10.0.1.2
tikv_servers:
- host: 10.0.1.7
# ssh_port: 22
# port: 20160
# status_port: 20180
# deploy_dir: "/tidb-deploy/tikv-20160"
# data_dir: "/tidb-data/tikv-20160"
# log_dir: "/tidb-deploy/tikv-20160/log"
# numa_node: "0,1"
# # The following configs are used to overwrite the `server_configs.tikv` values.
# config:
# server.grpc-concurrency: 4
# server.labels: { zone: "zone1", dc: "dc1", host: "host1" }
- host: 10.0.1.8
- host: 10.0.1.9
## 可选组件
cdc_servers:
- host: 10.0.1.1
port: 8300
deploy_dir: "/tidb-deploy/cdc-8300"
data_dir: "/tidb-data/cdc-8300"
log_dir: "/tidb-deploy/cdc-8300/log"
# gc-ttl: 86400
- host: 10.0.1.2
port: 8300
deploy_dir: "/tidb-deploy/cdc-8300"
data_dir: "/tidb-data/cdc-8300"
log_dir: "/tidb-deploy/cdc-8300/log"
# gc-ttl: 86400
monitoring_servers:
- host: 10.0.1.10
# ssh_port: 22
# port: 9090
# deploy_dir: "/tidb-deploy/prometheus-8249"
# data_dir: "/tidb-data/prometheus-8249"
# log_dir: "/tidb-deploy/prometheus-8249/log"
grafana_servers:
- host: 10.0.1.10
# port: 3000
# deploy_dir: /tidb-deploy/grafana-3000
4.执行部署
执行部署命令前,先使用 check 及 check --apply 命令检查和自动修复集群存在的潜在风险:
- 1.检查集群存在的潜在风险:
tiup cluster check ./topology.yaml --user root [-p] [-i /home/root/.ssh/gcp_rsa]
- 2.自动修复集群存在的潜在风险:
tiup cluster check ./topology.yaml --apply --user root [-p] [-i /home/root/.ssh/gcp_rsa]
- 3.部署 TiDB 集群:
tiup cluster deploy tidb-test v5.4.0 ./topology.yaml --user root [-p] [-i /home/root/
# 注意版本号问题
预期日志结尾输出 Deployed cluster `tidb-test` successfully 关键词,表示部署成功。
- 4.查看信息
#1.查集群信息,包括集群名称、部署用户、版本、密钥信息等:
tiup cluster list
#2.检查 tidb-test 集群情况(未启动状态为 Down/inactive)
tiup cluster display tidb-test
- 5.启动集群
# 启动集群
tiup cluster start tidb-test
启动集群操作会按 PD -> TiKV -> Pump -> TiDB -> TiFlash -> Drainer -> TiCDC -> Prometheus -> Grafana -> Alertmanager 的顺序启动整个 TiDB 集群所有组件
预期结果输出 Started cluster `tidb-test` successfully,表示启动成功。
# 该命令支持通过 -R 和 -N 参数来只启动部分组件。
例如,下列命令只启动 PD 组件:
tiup cluster start 集群名 -R pd
下列命令只启动 1.2.3.4 和 1.2.3.5 这两台机器上的 PD 组件:
tiup cluster start 集群名 -N 1.2.3.4:2379,1.2.3.5:2379
# 注意
若通过 -R 和 -N 启动指定组件,需要保证启动顺序正确(例如需要先启动 PD 才能启动 TiKV),否则可能导致启动失败。
# 登陆
使用普通启动方式后,可通过无密码的 root 用户登录数据库(已安装client)。
mysql -h 127.0.0.1 -P 4000 -uroot
- 6.编辑配置
# 编辑模式打开该集群的配置文件:
tiup cluster edit-config 集群名
5.扩容和缩容
以扩缩容TiCDC节点为例
- 1.扩容TiCDC节点
# 1. 添加节点信息到 scale-out.yaml 文件
编写 scale-out.yaml 文件:
cdc_servers:
- host: 10.0.0.7
gc-ttl: 86400
data_dir: /data/deploy/install/data/cdc-8300
# 2. tiup运行扩容命令
tiup cluster scale-out <cluster-name> scale-out.yaml
# 3. cdc server直接启动
cdc server --pd=http://10.0.0.7:2379 --log-file=ticdc_1.log --addr=0.0.0.0:8301 --advertise-addr=127.0.0.1:8301
- 2.缩容节点
# 缩容 TiCDC 节点
tiup cluster scale-in <cluster-name> --node 10.0.0.7:8300
查看集群状态
tiup cluster display <cluster-name>
- 特别注意
缩容和卸载组件有小bug,在缩容之后display还是down状态,在重启时会再次启动并失败。
# -------------重要!!-------------- #
# ----------------------------------- #
可以强制删除,加上--force 参数
并且在安装文件夹下:/root/.tiup/storage/cluster/clusters/集群名/
修改meta.yaml文件(可能还需要修改backup里最新的备份文件)
# ----------------------------------- #
# ----------------------------------- #
三、TiUP管理组件
# TiUP 主要通过以下一些命令来管理组件:
list:查询组件列表,用于了解可以安装哪些组件,以及这些组件可选哪些版本
install:安装某个组件的特定版本
update:升级某个组件到最新的版本
uninstall:卸载组件
status:查看组件运行状态
clean:清理组件实例
help:打印帮助信息,后面跟其他 TiUP 命令则是打印该命令的使用方法
1.查询组件列表
# 查看某个组件有哪些版本可以安装
tiup list ${component}
# 你也可以在命令中组合使用以下参数 (flag):
--installed:查看本地已经安装了哪些组件,或者已经安装了某个组件的哪些版本
--all:显式隐藏的组件
--verbose:显式所有列(安装的版本、支持的平台)
# 示例一:查看当前已经安装的所有组件
tiup list --installed
2.安装组件
你可以使用 tiup install 命令来安装组件。该命令的用法如下:
tiup install <component>:安装指定组件的最新稳定版tiup install <component>:[version]:安装指定组件的指定版本
1.示例一:使用 TiUP 安装最新稳定版的 TiDB
tiup install tidb
2.示例二:使用 TiUP 安装 nightly 版本的 TiDB
tiup install tidb:nightly
3.示例三:使用 TiUP 安装 v5.4.0 版本的 TiKV
tiup install tikv:v5.4.0
3.升级组件
在官方组件提供了新版之后,你可以使用 tiup update 命令来升级组件。除了以下几个参数,该命令的用法基本和 tiup install 相同:
--all:升级所有组件
--nightly:升级至 nightly 版本
--self:升级 TiUP 自己至最新版本
--force:强制升级至最新版本
# 示例一:升级所有组件至最新版本
tiup update --all
4.运行组件
# 安装完成之后,你可以使用 tiup <component> 命令来启动相应的组件:
tiup [flags] <component>[:version] [args...]
Flags:
-T, --tag string 为组件实例指定 tag
1.示例: 运行 v5.4.0 版本的 TiDB
tiup tidb:v5.4.0
2.示例:指定 tag 运行 TiKV
tiup --tag=experiment tikv
5.清理组件实例
你可以使用 `tiup clean` 命令来清理组件实例,并删除工作目录。
如果在清理之前实例还在运行,会先 kill 相关进程。该命令用法如下:
tiup clean [tag] [flags]
支持以下参数:
--all:清除所有的实例信息
其中 tag 表示要清理的实例 tag,如果使用了 `--all` 则不传递 tag。
1.清理 tag 名称为 `experiment` 的组件实例
tiup clean experiment
2.清理所有组件实例(清理所有数据)
tiup clean --all
6.卸载组件
TiUP 安装的组件会占用本地磁盘空间,如果不想保留过多老版本的组件,可以先查看当前安装了哪些版本的组件,然后再卸载某个组件。
你可以使用 `tiup uninstall` 命令来卸载某个组件的所有版本或者特定版本,也支持卸载所有组件。该命令用法如下:
tiup uninstall [component][:version] [flags]
支持的参数:
`--all`:卸载所有的组件或版本
`--self`:卸载 TiUP 自身
component 为要卸载的组件名称,version 为要卸载的版本,这两个都可以省略,省略任何一个都需要加上 `--all` 参数:
若省略版本,加 `--all` 表示卸载该组件所有版本
若版本和组件都省略,则加 `--all` 表示卸载所有组件及其所有版本
1.卸载 v5.4.0 版本的 TiDB
tiup uninstall tidb:v5.4.0
2.卸载所有版本的 TiKV
tiup uninstall tikv --all
3.卸载所有已经安装的组件
tiup uninstall --all
四、常用设置及问题处理
1.去重数据,重建联合索引
--------分段统计,数据库太大会报错内存不足
insert into temp111
(
select barcode,operation_status,status from
(select * from billtrack where id between '55000000' and '60000000'
) a
group by a.barcode,a.operation_status,a.status having count(1)>1
)
---------设置事务内存
set tidb_mem_quota_query = '28589934592'
---------删除重复数据
delete from billtrack where id in
(
select max(id) from
(
select b.id,b.barcode,b.operation_status,b.status from temp111 a
inner join billtrack b
on a.barcode=b.barcode and a.operation_status=b.operation_status and a.status=b.status
) c
group by c.barcode having count(1)>1
)





