SQL Server远程数据库链接 事务性能监控 慢查询 索引

一、远程数据库链接
SQL Server链接服务器不仅可以帮助你链接SQL Server,还可以链接Oracle、Access、MySQL、ODBC数据源。
1. 直接链接SQL Server
- 两台SQL的服务器分别为SQL1.abc.com和SQL2.abc.com
-
在SQL1上新建链接服务器:
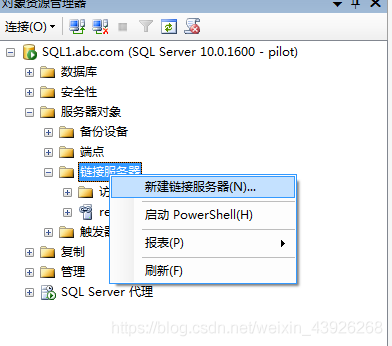
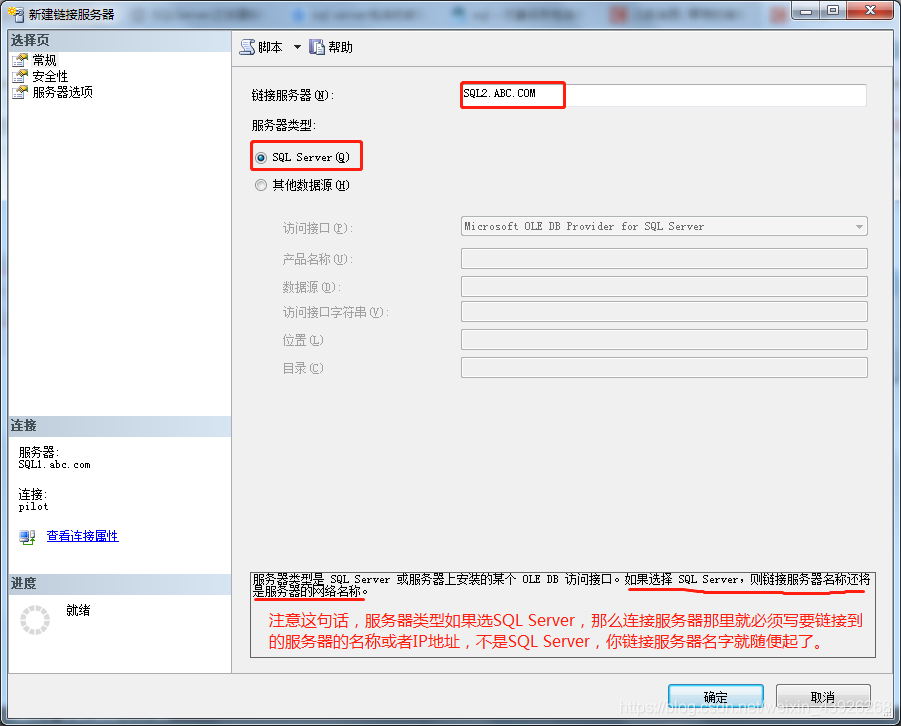
- 接下来我们左边选择“安全性”,配置远程链接的账号密码:
这里一定注意配置登录映射的时候,“本地登录”的账号必须与你本地数据库登录的账号一致,即图中1与2处的账号要相同。如果不相同,会出现后面“访问遭拒绝,不存在登录映射的问题”。一旦配置出错,建议关闭,退出重新来过,重新创建链接服务器,否则会出现各种奇奇怪怪的报错,比如,明明输入了账号sa,提示输入的账号是s,登录失败。
下面是错误的示范:
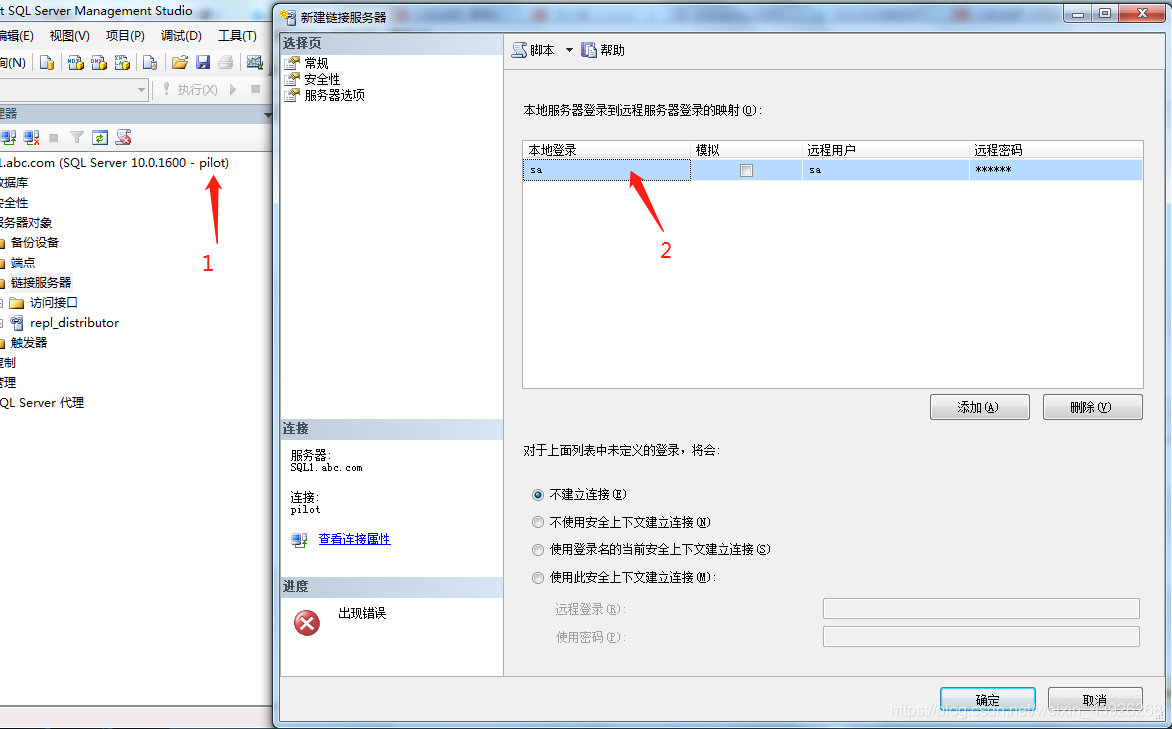

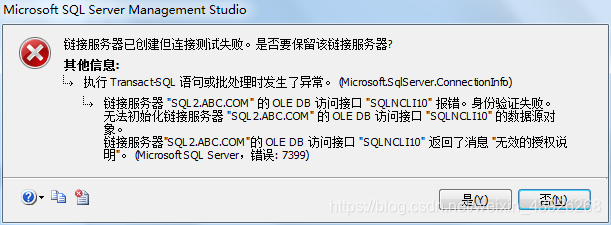
正确的示范:

注意这个选项:

- 这个选项是专门针对有多个数据库登录用户的情况,如果没有在上面进行登录映射定义,他们就无法建立连接。还有一个“使用此安全上下文建立连接”,这个选项可以不配置前面的登录映射,直接在这里配置远程的登录名和密码,全部使用这个账号密码建立连接。
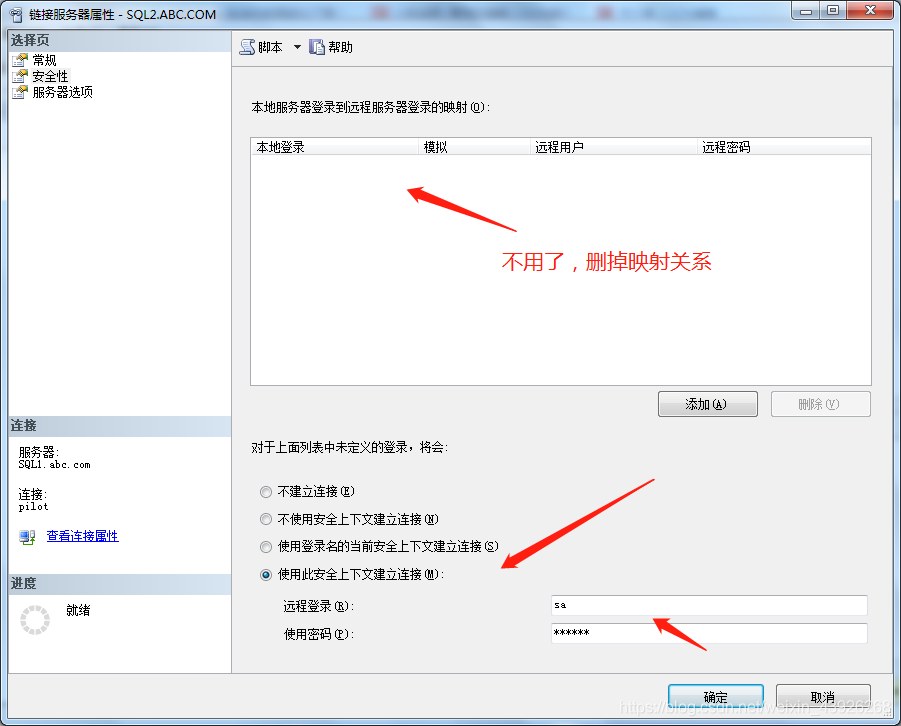
建立链接服务器完成之后(如下图),那怎么使用呢?
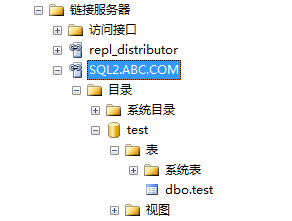
[链接服务器名或ip地址].数据库名.架构名.表名
select * from [SQL2.abc.com].test.dbo.test
注意:这里的链接服务器名一定要用中括号"[]"括起来,不然又会报错:

2. ODBC链接SQL Server
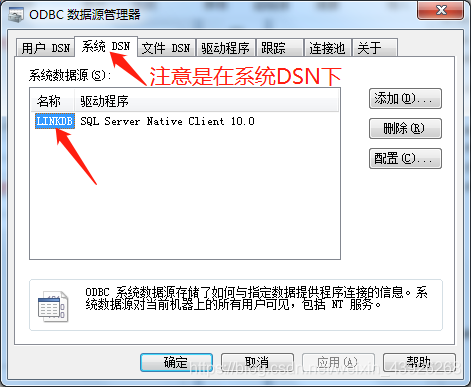

安全性设置和之前一样就不说了。
3. ODBC链接MySQL
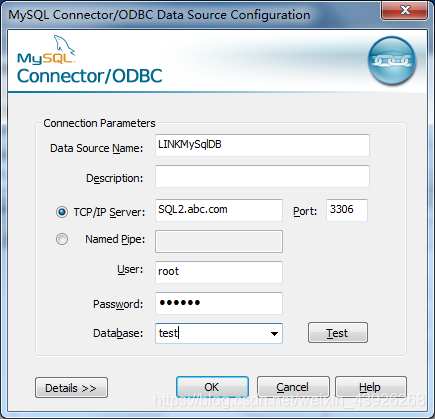
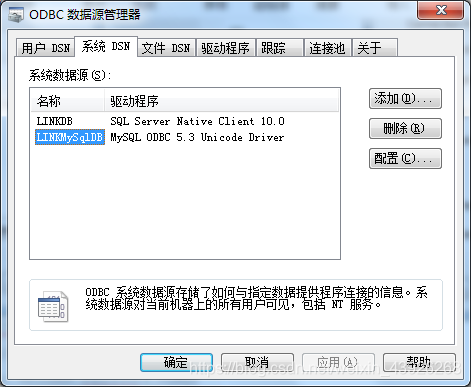
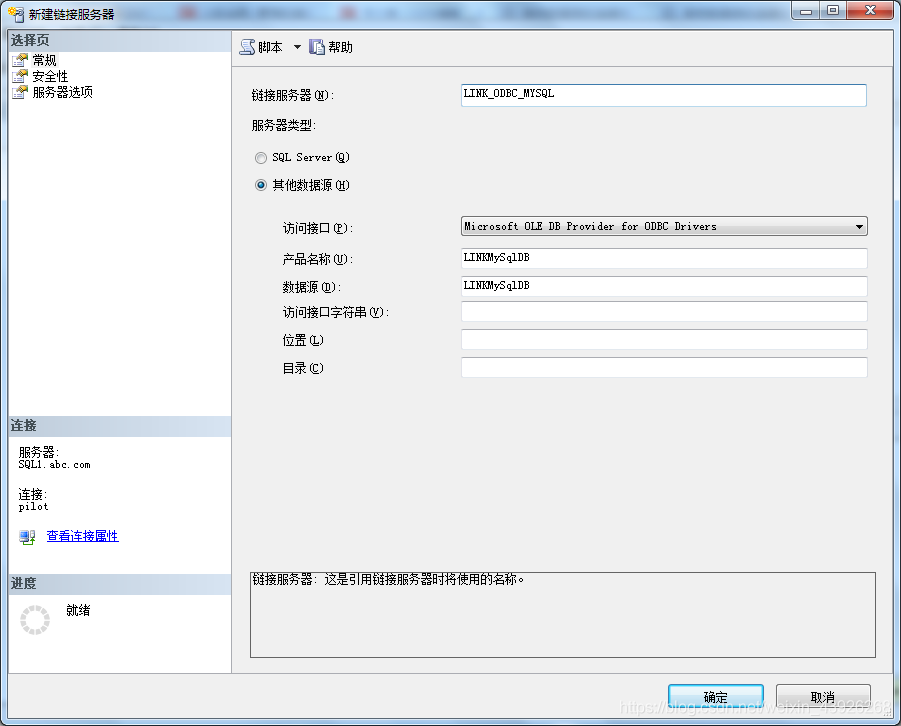
查询:
SELECT * FROM OPENQUERY (LINK_ODBC_MYSQL, 'select * from test')
添加:
Insert openquery(LINKDB_MYSQL, 'select * from test') (Address) values('云南')
删除:
delete openquery(LINKDB_MYSQL, 'SELECT * FROM test where id=2')
或者:
delete openquery(LINKDB_MYSQL, 'SELECT * FROM test ')where id=5
更新:
update openquery(LINKDB_MYSQL, 'SELECT * FROM test') SET Address = '北京' WHERE id = 1
- 如果出现链接好之后,查询提示“Source character set not supported by client”说明数据库驱动版本不够,像上面我使用的是mysql8.0.13,但是我的odbc驱动是5.3,就会出现这个问题,更换odbc驱动为8.0.18之后正常访问。
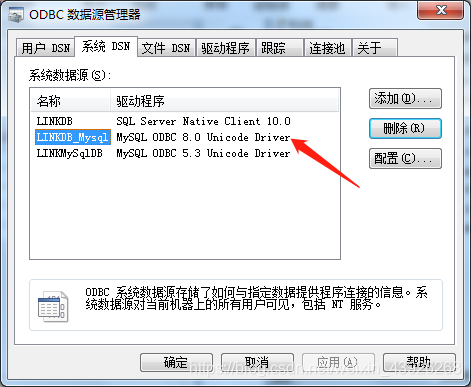
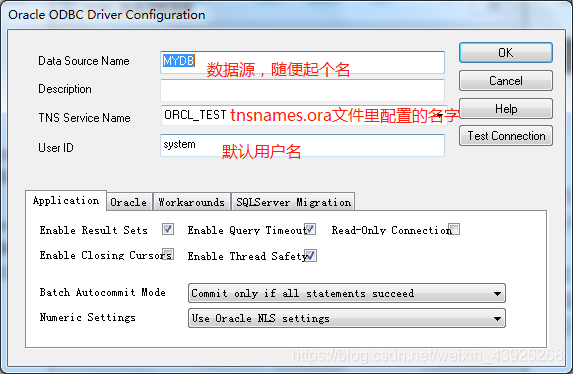
4. ODBC链接Oracle
- 基本跟链接MySQL差不多,驱动不同而已。
首先需要安装Oracle驱动instant client,点我这个链接直接去Oracle官网找。根据自己的需要下载相关的驱动及工具包。我这里只需要basic(这是必须的)和odbc驱动(这也是必须的,因为需要创建ODBC数据源连接Oracle数据库),因为我是64位的,所以我需要下64位的包,如下图:

- 这个安装教程其实很简单,我有一个文档在我的下载资源里,这里也简单写写吧,方便没有积分的朋友。
-
将两个压缩包解压,将里面的内容合并到同一个文件夹中。否则后面安装ODBC时会提示找不到instant client。
我合并后的文件夹instantclient_11_2放在路径:
C:\Program Files\Oracle\instantclient_11_2,在C:\Program Files\Oracle\instantclient_11_2
目录下创建子文件夹network\admin,
绝对路径也就是:
C:\Program Files\Oracle\instantclient_11_2\network\admin,
在该目录下新建文件tnsnames.ora和sqlnet.ora。
文件中的详细内容配置可自行百度,关于sqlnet和tnsnames文件的作用也自行百度。
sqlnet.ora文件内容如下:
SQLNET.AUTHENTICATION_SERVICES= (NTS)
NAMES.DIRECTORY_PATH= (TNSNAMES, EZCONNECT)
tnsnames.ora文件内容如下:
ORCL_TEST=
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 你的Oracle主机名)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = 服务名,我这里是默认的orcl)
)
)
设置系统环境变量:
Path C:\Program Files\Oracle\instantclient_11_2
# 在Path后面追加instantclient路径
TNS_ADMIN C:\Program Files\Oracle\instantclient_11_2\network\admin
# tnsnames.ora所在路径
NLS_LANG SIMPLIFIED CHINESE_CHINA.ZHS16GBK
# 设置Oracle字符语言集,此字符集支持中文
- 进入到instantclient_11_2目录,运行刚合并进来的odbc_install.exe安装ODBC驱动。直接双击运行一闪而过,看不到是否安装成功,可以通过cmd运行查看运行结果。
-
至此,配置全部完成。可以通过ODBC创建数据源连接Oracle数据库了,如果在程序中调用DSN时出现驱动程序与应用程序体系结构不匹配,则说明所安装的版本不正确(若安装的64位则更换32位即可解决)。
SELECT * FROM OPENQUERY (ORCL, 'select * from test')

增删改查写法参考MySQL部分
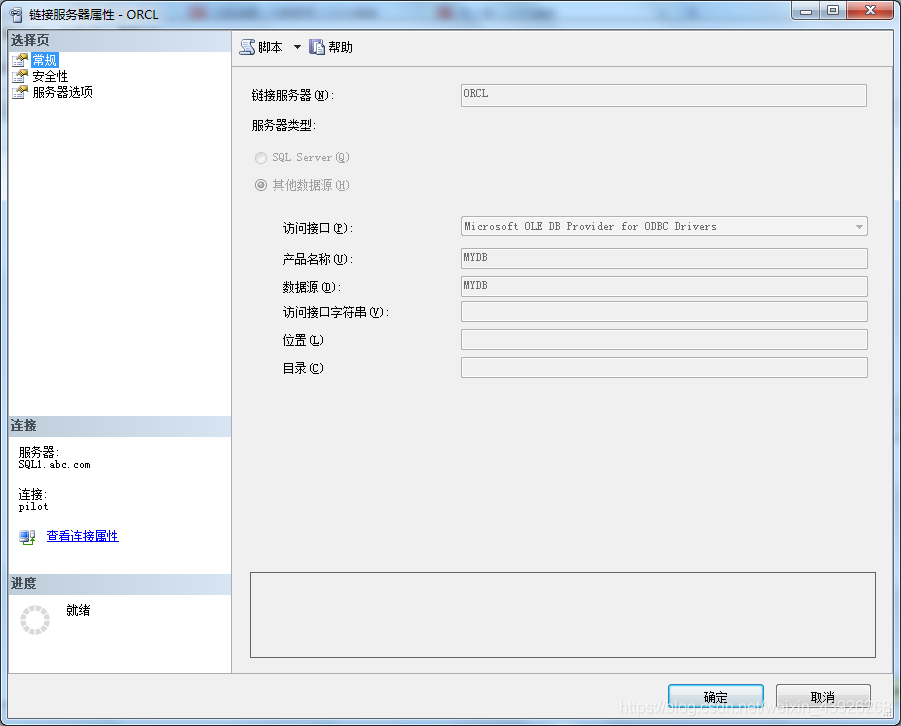
5. 使用Oracle OLEDB驱动
- 使用Oracle OLEDB驱动提供程序链接Oracle数据库
- Oracle Data Access Components (ODAC)
这种方法与第四种instant client创建odbc驱动链接的方式存在冲突,OLEDB驱动安装之后也会安装instant client的basic组件。所以需要删除之前的Path环境变量中instant client的路径,修改为稍后要创建的新路径。或者将之前的ODBC驱动重新安装到这个instant client目录中,不再使用之前的instant client。
首先需要下载OLEDB驱动,同样,我下载64位版本:https://www.oracle.com/database/technologies/odac-downloads.html

解压:
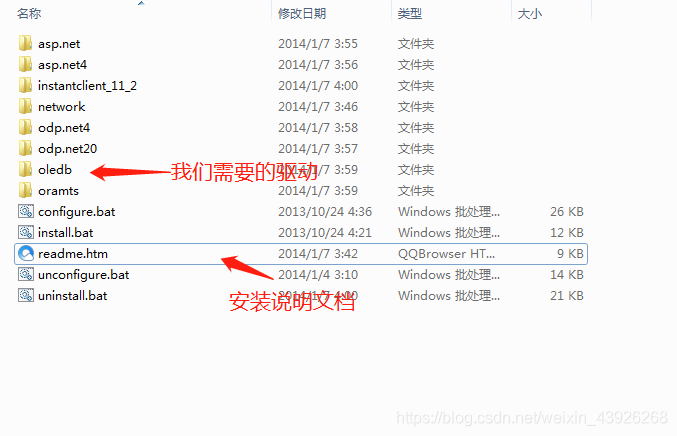
- 这个压缩包是包含了安装说明的文档的,里面有readme.htm。文档里也有讲,可以全部安装,也可以选择需要的组件进行安装。我这里就只安装我需要的就行了。在当前目录打开命令窗口,输入:
install.bat oledb c:\oracleOLEDB ODAC
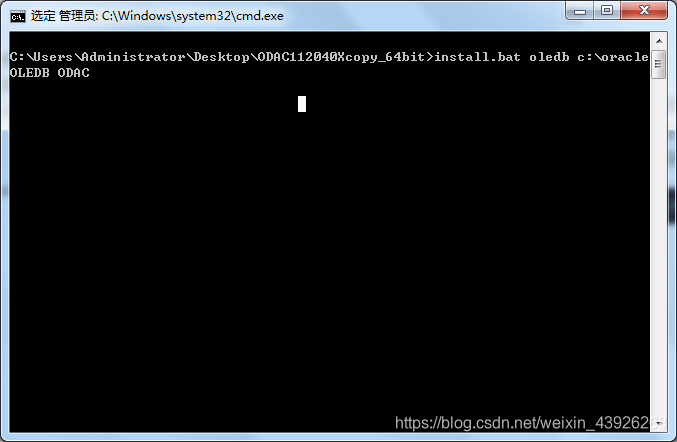
- 其中oledb代表要安装的组件,c:\oracleOLEDB为安装目录,ODAC为注册表项Oracle Home的名称,卸载的时候使用uninstall.bat(需要到安装目录下使用这个命令,而不是刚刚的解压目录里),带这个名字或者目录都行。卸载命令:
uninstall.bat all ODAC
- 安装完成之后,就会出现OraOLEDB.Oracle这个访问接口了

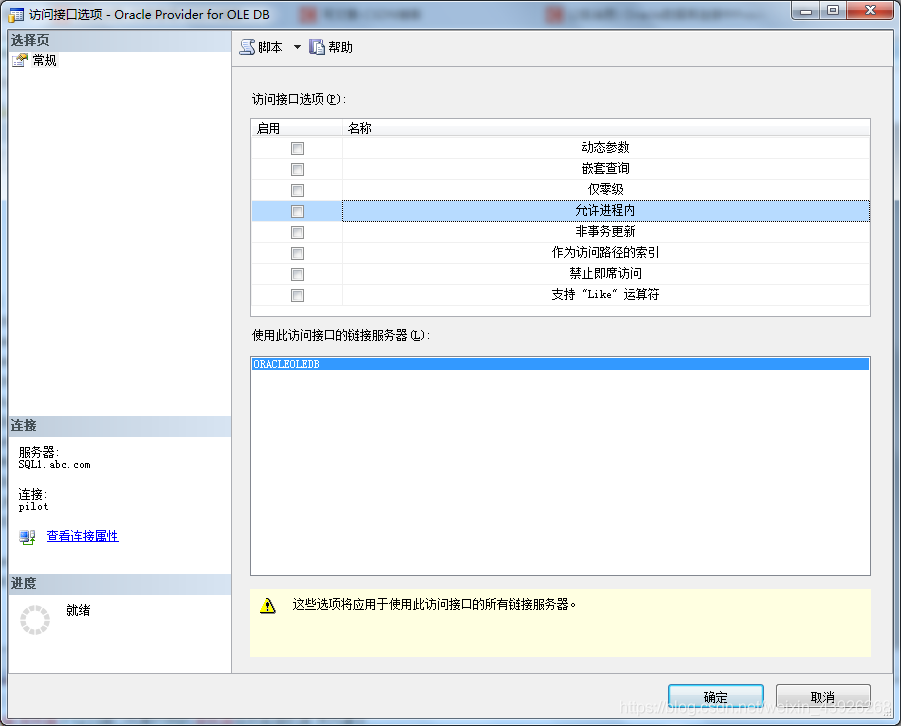
- 接口的属性里有一些设置选项,自己酌情勾选,建议勾选"允许进程内"。
别着急去创建链接服务器,在系统环境变量中,为Path添加“C:\oracleOLEDB;C:\oracleOLEDB\bin;”
(计算机属性-高级系统设置-高级-环境变量-系统环境变量-Path),如果之前安装过instant client,需要删除其路径,否则在SQL Server管理工具创建链接服务器时会卡死。
如果是供外部应用程序访问,还需要配置TNS_ADMIN和NLS_LANG环境变量,配置方式参考第四步。
最后创建链接服务器:
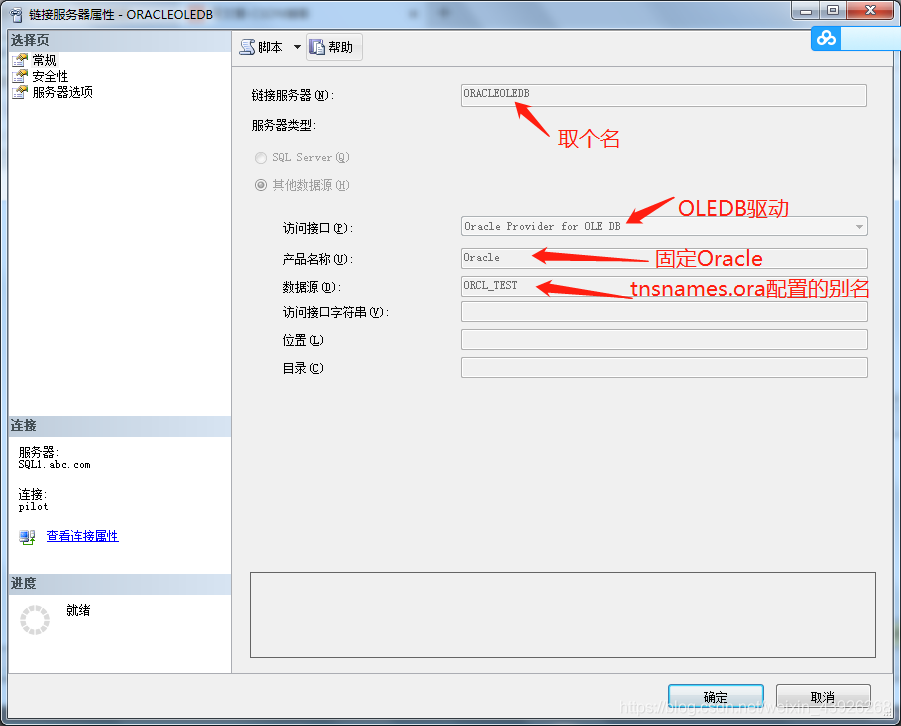
- 由于OLEDB驱动支持EZCONNECT,所以不配置tnsnames.ora也是可以的,使用IP:端口号/实例名也可以:
- 安全性设置不用说了,一样。
这种驱动创建的链接服务器可以使用下面这种方式进行查询,也可以使用前面的openquery方式查询。
select * from ORACLEOLEDB..SYSTEM.TEST
- SYSTEM是我TEST表创建时选择的方案,注意方案前面试两个点。注意Oracle区分大小写,否则会无法查询。
> 通过OleDB连接Oracle数据库,一般有两种provider
> A:provider=MSDAORA.1
> B:provider=OraOLEDB.Oracle
> 第一种为微软公司的oracle组件,第二种为oracle的访问组件。
> Oracle数据库经常使用的两种字符集
> C:英文:SIMPLIFIED CHINESE_CHINA.US7ASCII
> D:中文:SIMPLIFIED CHINESE_CHINA.ZHS16GBK
> A与C、D搭配,数据读写没有乱码问题,如果出现乱码,则修改系统级(非用户级)的环境变量nls_lang为数据库所使用的字符集,重启电脑即可。
> 缺点:不支持long/Clob/Blob大字段。
> B支持大字段,与D搭配最为完美。如果BC搭配使用,读出无乱码,写入为乱码,做为where条件传进去的中文参数为乱码。无法使用。如果数据库字符集为C,则只能使用A。如果要读取大字段,只得使用B新建连接
- MSDAORA仅支持32位,64位机器上可能已经没有带该驱动了。
下载链接:https://www.microsoft.com/zh-CN/download/details.aspx?id=5793

二、远程任务脚本
1. 直接访问方式
--直接使用远程命令报错提示:
SQL Server 阻止了对组件 'Ad Hoc Distributed Queries' 的 STATEMENT'OpenRowset/OpenDatasource' 的访问,因为此组件已作为此服务器安全配置的一部分而被关闭。系统管理员可以通过使用 sp_configure 启用 'Ad Hoc Distributed Queries'。有关启用 'Ad Hoc Distributed Queries' 的详细信息,请参阅 SQL Server 联机丛书中的 "外围应用配置器"。
--开启远程功能
exec sp_configure 'show advanced options',1
reconfigure
exec sp_configure 'Ad Hoc Distributed Queries',1
reconfigure
-- 方式一:
SELECT * FROM OPENDATASOURCE('SQLOLEDB',
'Data Source=192.168.18.184;uid=sa;pwd=123'
).test1.dbo.tt1 where 条件...
-- 方式二:
select * from opendatasource('msdasql',
'driver={sql server};server=192.168.18.184;uid=sa;pwd=123;'
).test1.dbo.tt1 where 条件...
2. 链接服务器方式
-- 添加链接服务器:
sp_addlinkedserver @server = N'链接服务器名',
@srvproduct = N' ',
@provider = N'SQLOLEDB',
@datasrc = N'远程服务器IP',
添加链接服务器登录
sp_addlinkedsrvlogin [ @rmtsrvname = ] '链接服务器名'
[ , [ @useself = ] 'false' ]
[ , [ @locallogin = ] '本地登录名' ]
[ , [ @rmtuser = ] '远程登录名' ]
[ , [ @rmtpassword = ] '远程密码' ]
这样访问远程服务器的就可以通过SQL
select * from 链接服务器名.远程数据名.远程所有者.远程表名
不用管远程服务器的地址所登录名,只能链接服务器名,不变,正式发装时,不能修改程序!
三、SQL Server 监控
1. Windows 事件日志(Event Log)

1.可以在运行中直接输入:eventvwr.msc /s 来启动事件查看器,界面如上:
2.也可以保存事件日志,或者是打开以保存的事件日志:

2. SQL Server Errorlog 文件
错误日志默认会保留7份,按照时间顺序,依次用文件扩展名.1,.2,...,.6,每重启一次服务器,文件扩展名都会加一,而时间最早的那个会被删除:
- 错误日志的位置是启动参数来决定的,可以在配置管理器中来查看:

- 查看错误日志:
--在错误日志中会记录的信息:
(1)SQL Server版本、Windows和处理器信息
(2)SQL Server的启动参数、认证模式、内存分配模式
(3)每个数据库是否能被正常打开,如果打不开,原因是什么
(4)数据库损坏相关的错误
(5)数据库备份与恢复的记录
(6)DBCC checkdb记录
(7)内存相关的错误、警告
(8)SQL Server调度出现异常时的警告,一般Server hang会有这些警告
(9)SQL Server IO操作遇到长时间延迟的警告
(10)SQL Server在运行过程中遇到的其他比较高级别的错误
(12)SQL Server内部的访问越界错误 Access Violation
(13)SQL Server服务关闭时间
--如果开启了一些设置,也会看到其他有用的信息:
(1)所有用户成功或失败的登入
(2)死锁以及参与者的信息
--在错误日志中不会记录的信息:
(1)阻塞问题。只要阻塞没有严重到影响SQL Server的线程调度,在错误日志中是不会记录的。
(2)普通性能问题,超时问题。如果性能问题不是由于内存使用异常、线程调度异常、IO子系统反应非常缓慢,而是由于表、语句涉及导致,那么也不会记录
(3)Windows层面异常。如果在Windows层面出现了工作不正常,或者服务器没响应,SQL Server是无法自我判断的。
3. 性能监视器(SQL Server Profiler)
在系统中搜索:SQL Server Profiler

在 Windows 中启动系统监视器
在“开始”菜单上,指向“运行”,在“运行”对话框中键入“perfmon”,然后选择“确定” 。
- 1.性能监视器
- 2.资源监视器

4. SQL Trace 文件
--1. 查询默认跟踪是否开启
select configuration_id,
name,
value,
value_in_use,
description,
is_dynamic,
is_advanced
from sys.configurations
where configuration_id = 1568
--2. 当传递特定跟踪的 ID 时,fn_trace_getinfo 将返回有关该跟踪的信息
--跟踪的属性:
1= 跟踪选项。 有关详细信息,请参阅 sp_trace_create (Transact-SQL) 中的 @options。
2 = 文件名
3 = 最大大小
4 = 停止时间
5 = 当前跟踪状态。 0 = 停止。 1 = 正在运行。
select * from fn_trace_getinfo(0)
--3. 查询默认跟踪信息
select
loginname '登录账号',
loginsid,
spid '会话id',
hostname '主机名',
applicationname '应用程序名',
servername '服务器名',
databasename '数据库名',
objectname '对象名',
tc.category_id ,
tc.name '类别名称',
te.trace_event_id ,
tc.name '事件名称',
eventsubclass, --0:begin, 1:commit
textdata,
starttime
from fn_trace_gettable('D:\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\Log\log_93.trc',0) t
inner join sys.trace_events te
--跟踪事件
on t.eventclass = te.trace_event_id
inner join sys.trace_categories as tc
--事件类别
on te.category_id = tc.category_id
where databasename = db_name() and
objectname is null
5. 动态性能视图 sys.dm_os_wait_stats
返回执行的线程所遇到的所有等待的相关信息。可以使用该聚合视图来诊断 SQL Server 以及特定查询和批处理的性能问题。
6. SQLDiag工具(自动日志信息收集)
SQLdiag是一个命令行实用工具,默认情况下,在C:Program FilesMicrosoft SQL Server100ToolsBinn目录下可用。
- 1>internal文件夹,包含了由该工具创建的日志文件,以及一些其他文件
- 2>SQL Server默认跟踪、SQLDUMPER_ERRORLOG
- 3>一个文本文件的MSINFO32输出
- 4>机器名_实例名_sp_sqldiag_Shutdown.OUT文本文件,其中包含了下列数据:
4.1>所有错误日志
4.2>各种系统存储过程的输出,如sp_configure、sp_who、sp_lock、sp_helpdb从而获得SQL Server实例和数据库配置详细信息
4.3>各种动态管理视图和系统目录的输出,如sys.sysprocesses、sys.dm_exec_sessions和sys.dm_os_wait_stats,以获得以下额外的重要信息:
4.3.1>了解实例的内存使用情况
4.3.2>所有SQL Server PerfMon计数器的当前值的快照
4.3.3>SQL Server等待统计的快照
4.3.4>SQL Server实例中的会话和活跃请求的状态,以及相关联的输入缓冲区
4.3.5>SQL Server调度器的状态
四、慢查询检查 dm_exec_query_stats

1. 指定时间段
-- 查看指定时间段慢查询
SELECT
(total_elapsed_time / execution_count)/1000 N'平均时间ms'
,total_elapsed_time/1000 N'总花费时间ms'
,total_worker_time/1000 N'所用的CPU总时间ms'
,total_physical_reads N'物理读取总次数'
,total_logical_reads/execution_count N'每次逻辑读次数'
,total_logical_reads N'逻辑读取总次数'
,total_logical_writes N'逻辑写入总次数'
,execution_count N'执行次数'
,SUBSTRING(st.text, (qs.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset END
- qs.statement_start_offset)/2) + 1) N'执行语句'
,creation_time N'语句编译时间'
,last_execution_time N'上次执行时间'
FROM
sys.dm_exec_query_stats AS qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) as st
WHERE
SUBSTRING(st.text, (qs.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset END
- qs.statement_start_offset)/2) + 1) not like '%fetch%'
and creation_time between '2020-10-07 01:35:00.000' and '2020-10-08 01:35:00.000'
-- 在此处指定查询时间段
ORDER BY
-- 按最后执行时间降序
total_elapsed_time / execution_count DESC;
2. 历史慢查询
-- 排查历史慢查询
SELECT TOP 20
[总IO] = (qs.total_logical_reads + qs.total_logical_writes)
, [平均IO] = (qs.total_logical_reads + qs.total_logical_writes) /
qs.execution_count
, qs.execution_count as 执行计数
, SUBSTRING (qt.text,(qs.statement_start_offset/2) + 1,
((CASE WHEN qs.statement_end_offset = -1
THEN LEN(CONVERT(NVARCHAR(MAX), qt.text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS [Individual Query]
, qt.text AS [父查询]
, DB_NAME(qt.dbid) AS 数据库
, qp.query_plan as 执行计划
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) as qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
ORDER BY [平均IO] DESC
3. 正在执行的慢查询
-- 当前正在执行的慢查询:
SELECT TOP 1 ST.transaction_id AS TransactionID ,
st.session_id ,
DB_NAME(DT.database_id) AS DatabaseName ,
ses.host_name ,
ses.login_name ,
ses.status,
AT.transaction_begin_time AS TransactionStartTime ,
s.text ,
c.connect_time ,
DATEDIFF(second, AT.transaction_begin_time, GETDATE()) "exec_time(s)" ,
DATEDIFF(minute, AT.transaction_begin_time, GETDATE()) AS Tran_run_time ,
CASE AT.transaction_type
WHEN 1 THEN 'Read/Write Transaction'
WHEN 2 THEN 'Read-Only Transaction'
WHEN 3 THEN 'System Transaction'
WHEN 4 THEN 'Distributed Transaction'
END AS TransactionType ,
CASE AT.transaction_state
WHEN 0 THEN 'Transaction Not Initialized'
WHEN 1 THEN 'Transaction Initialized & Not Started'
WHEN 2 THEN 'Active Transaction'
WHEN 3 THEN 'Transaction Ended'
WHEN 4 THEN 'Distributed Transaction Initiated Commit Process'
WHEN 5 THEN 'Transaction in Prepared State & Waiting Resolution'
WHEN 6 THEN 'Transaction Committed'
WHEN 7 THEN 'Transaction Rolling Back'
WHEN 8 THEN 'Transaction Rolled Back'
END AS TransactionState
FROM sys.dm_tran_session_transactions AS ST
INNER JOIN sys.dm_tran_active_transactions AS AT ON ST.transaction_id = AT.transaction_id
INNER JOIN sys.dm_tran_database_transactions AS DT ON ST.transaction_id = DT.transaction_id
LEFT JOIN sys.dm_exec_connections AS C ON st.session_id = c.session_id
LEFT JOIN sys.dm_exec_sessions AS ses ON c.session_id = ses.session_id
CROSS APPLY sys.dm_exec_sql_text(c.most_recent_sql_Handle) s
WHERE DATEDIFF(second, AT.transaction_begin_time, GETDATE()) > 2
五、索引相关命令
1.新建索引
-- 创建唯一非聚集索引
create unique nonclustered --表示创建唯一非聚集索引
index UQ_NonClu_StuNo --索引名称
on Student(S_StuNo) --数据表名称(建立索引的列名)
with
(
pad_index=on, --表示使用填充
fillfactor=50, --表示填充因子为50%
ignore_dup_key=on, --表示向唯一索引插入重复值会忽略重复值
statistics_norecompute=off --表示启用统计信息自动更新功能
--创建聚集索引
create clustered index Clu_Index
on Student(S_StuNo)
with (drop_existing=on)
--创建非聚集索引
create nonclustered index NonClu_Index
on Student(S_StuNo)
with (drop_existing=on)
--创建唯一索引
create unique index NonClu_Index
on Student(S_StuNo)
with (drop_existing=on)
# PS:当 create index 时,如果未指定 clustered 和 nonclustered,那么默认为 nonclustered
--创建非聚集复合索引
create nonclustered index Index_StuNo_SName
on Student(S_StuNo,S_Name)
with(drop_existing=on)
--创建非聚集复合索引,未指定默认为非聚集索引
create index Index_StuNo_SName
on Student(S_StuNo,S_Name)
with(drop_existing=on)
-----------------------
在 CREATE INDEX 语句中使用 INCLUDE 子句,可以在创建索引时定义包含的非键列(即覆盖索引),其语法结构如下:
CREATE NONCLUSTERED INDEX 索引名
ON { 表名| 视图名 } ( 列名 [ ASC | DESC ] [ ,...n ] )
INCLUDE (<列名1>, <列名2>, [,… n])
-----------------------
--创建非聚集覆盖索引
create nonclustered index NonClu_Index
on Student(S_StuNo)
include (S_Name,S_Height)
with(drop_existing=on)
--创建非聚集覆盖索引,未指定默认为非聚集索引
create index NonClu_Index
on Student(S_StuNo)
include (S_Name,S_Height)
with(drop_existing=on)
# PS:聚集索引不能创建包含非键列的索引。
--创建非聚集筛选索引
create nonclustered index Index_StuNo_SName
on Student(S_StuNo)
where S_StuNo >= 001 and S_StuNo <= 020
with(drop_existing=on)
--创建非聚集筛选索引,未指定默认为非聚集索引
create index Index_StuNo_SName
on Student(S_StuNo)
where S_StuNo >= 001 and S_StuNo <= 020
with(drop_existing=on)
2.修改索引
--修改索引语法
ALTER INDEX { 索引名| ALL }
ON <表名|视图名>
{ REBUILD | DISABLE | REORGANIZE }[ ; ]
REBUILD:表示指定重新生成索引。
DISABLE:表示指定将索引标记为已禁用。
REORGANIZE:表示指定将重新组织的索引叶级。
--禁用名为 NonClu_Index 的索引
alter index NonClu_Index on Student disable
3.删除和查看
--查看指定表 Student 中的索引
exec sp_helpindex Student
--删除指定表 Student 中名为 Index_StuNo_SName 的索引
drop index Student.Index_StuNo_SName
--检查表 Student 中索引 UQ_S_StuNo 的碎片信息
dbcc showcontig(Student,UQ_S_StuNo)
--整理 Test 数据库中表 Student 的索引 UQ_S_StuNo 的碎片
dbcc indexdefrag(Test,Student,UQ_S_StuNo)
--更新表 Student 中的全部索引的统计信息
update statistics Student
4.重建索引
随着数据的数据量的急剧增加,数据库的性能也会明显的有些缓慢
通过Sql代码
DBCC SHOWCONTIG('表名')
可以查看当前表的索引碎片情况,出来的结果大概如下:
DBCC SHOWCONTIG 正在扫描 'tblWFProcessRelatedDataInstanceHistory' 表...
表: 'tblWFProcessRelatedDataInstanceHistory' (933630419);索引 ID: 1,数据库 ID: 8
已执行 TABLE 级别的扫描。
- 扫描页数................................: 727
- 扫描区数..............................: 96
- 区切换次数..............................: 95
- 每个区的平均页数........................: 7.6
- 扫描密度 [最佳计数:实际计数].......: 94.79% [91:96]
- 逻辑扫描碎片 ..................: 3.16%
- 区扫描碎片 ..................: 76.04%
- 每页的平均可用字节数........................: 143.6
- 平均页密度(满).....................: 98.23%
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
其中有些很重要的指标,如扫描密度、扫描碎片等。
最佳计数与实际计数相当时说明索引是比较好的,如相差太多,就必须可以重新建或组织索引。
重建索引命令:
# 指定表名:
DBCC DBREINDEX (Table, '', 70) (使用填充因子值 70 重建 Table表上的所有索引)
第一个参数是要重建索引的表名,第二个参数指定索引名称,空着就表示所有,第三个参数叫填充因子,是指索引页的数据填充程度,0表示使用先前的值,100表示每个索引页都填满,这时查询效率最高,但插入索引时会移动其它索引,可根据实际情况来设置。
DBCC DBREINDEX('Table')
# 对全库:
exec sp_msforeachtable 'DBCC DBREINDEX(''?'')'





